Welcome to My Blog!
-
SD基本概念及规格
基本概念
-
MMC: Multi Media Card, 即多媒体卡。它是一种非易失性存储器件,体积小巧,容量大,耗电量低,传输速度快,广泛应用于消费电子产品中。
-
SD: Secure Digital Memory Card,即安全数码卡。它在MMC的基础上发展而来,相比MMC它有两个主要优势:
- SD卡强调数据的安全,可以设定存储的使用权限,防止数据被他人复制。
- 传输速率比2.11版的MMC卡快。
在数据传输和物理规范上,SD卡向前兼容了MMC卡,所有支持SD卡的设备也支持MMC卡。
-
SDIO: Secure Digital Input and Output Card,即安全数字输入输出卡。SDIO是在SD标准上定义了的一种外设接口,通过SD的I/O引脚来连接外围设备,并且通过SD上的I/O数据位与这些外围设备进行数据传输。如下图中的一些设备: GPS、相机、WIFI、调频广播、条形码读卡器、蓝牙等。

-
相关网址
- sd官网: https://www.sdcard.org
-
Simple Specification 下载地址: https://www.sdcard.org/downloads/pls/index.html

SD家族
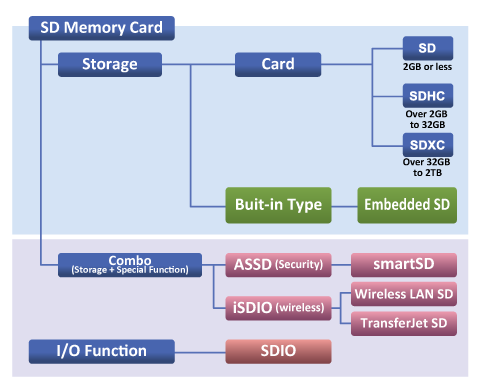
SD存储卡分类

-
根据容量划分
-
SD(SDSC): Standard Capacity SD Memory Card: Up to and including 2GB, using FAT12 and FAT16 file systems. All versions of the PLS define.
-
SDHC: High Capacity SD Memory Card: More than 2GB and up to and including 32GB, using FAT32 file system. It is defined from the PLS Ver2.00.
-
SDXC: Extended Capacity SD Memory Card: More than 32GB and up to and including 2TB, using exFAT file system.
The Part 1 PLS Ver3.00 or later and Part 2 FSS Ver3.00 or later 支持上述所有容量类型的SD卡
-
-
根据体积划分
- SD: Standard Size SD Memory Card
- miniSD
- microSD
-
根据读写方式划分
- Read/Write(RW) cards.
- Read Only Memory(ROM) cards.
-
根据工作电压划分
- High Voltage SD Memory Cards that can operate the voltage range of 2.7 - 3.6V.
- UHS-II SD Memory Card that can operate the voltage range VDD1: 2.7 - 3.6V, VDD2: 1.70 - 1.95V.
UHS-II: Ultra High Speed Phase II
SD支持的总线速率模式
Bus Speed Mode(using 4 parallel data lines)
-
Default Speed Mode: 3.3V signaling, Frequency up to 25MHZ, up to 12.5MB/sec
-
High Speed Mode: 3.3V signaling, Frequency up to 50MHZ, up to 25MB/sec
-
SDR12: UHS-I 1.8V signaling, Frequency up to 25MHZ, up to 12.5MB/sec
-
SDR25: UHS-I 1.8V signaling, Frequency up to 50MHZ, up to 25MB/sec
-
SDR50: UHS-I 1.8V signaling, Frequency up to 100MHZ, up to 50MB/sec
-
SDR104: UHS-I 1.8V signaling, Frequency up to 208MHZ, up to 104MB/sec
-
DDR50: UHS-I 1.8V signaling, Frequency up to 50MHZ, sampled on both clock edges, up to 50MB/sec
-
FH156: UHS-II Full Duplex mode up to 156MB/sec at 52MHZ in Range B.
-
HD312: UHS-II Half Duplex with 2 Lanes mode up to 312MB/sec at 52MHZ in Range B.
SDR: Single Data Rate signaling, 单边数据采样,要么上升沿采样,要么下降沿采样 DDR: Double Data Rate signaling, 双边数据采样,双边沿采样
-
-
SD Commands
SD总线协议
-
SD总线之间的通信是基于命令和数据比特流的。它们都是开始于起始位,终止于结束位。
-
Command: 一个命令代表了一个操作的开始。命令总是由主机发送给单个(addressed command)或所有(broadcast command)的卡。命令是通过CMD线串行传输的。
-
Response: a response is a token that is sent from an addressed card, or (synchronously) from all connected cards, to the host as an answer to a previously received command. A response is transferred serially on the CMD line.
-
Data: data can be transferred from the card to the host or vice versa. Data is transferred via the data lines.
-
-
卡的寻址是通过session address实现的。它是在卡的初始化阶段就被分配好的。SD总线中最基础transaction 就是 command/response。这种模式下,总线直接通过命令或响应的结构体进行信息传递。除此之外,其他操作有数据传递。
数据传输是以block为单位的。数据块后面总是带有CRC校验位。数据传输分为单块和多块数据传输。多块数据传输通常由stop命令来结束数据传输操作。
主机(HOST)可以配置数据传输方式为单块或多块。
在块写操作中,使用了一种简单的等待机制。通过判断DATA0信号状态来判断卡是否busy还是ready。
-
command and response
-
都是由start bit(0)开始,由end bit(1)终止
-
命令长度为48bits,响应长度为48bits或136bits
-
都包含CRC校验位
-
CMD line上的数据传输方式: MSB(Most Significant Bit) 先传输,LSB(Least Significant Bit)后传输


-
-
data packet format
-
Usual data(8-bit width): 在字节之间先传输低字节,在字节内部先传输高比特位。
-
Wide width data(SD Memory Register): 共有512 bit,先传输高比特位,后传输低比特位。

-
命令类型
-
下面是4种用于控制SD卡的命令:
-
Broadcast commands(bc), no response.
-
Broadcast commands with response(bcr)
-
Address(point-to-point) commands(ac) no data transfer on DAT 由HOST发送到指定的卡设备,没有数据传输
-
Address(point-to-point) data transfer commands(adtc) data transfer on DAT 由HOST发送到指定的卡设备,且伴随有数据传输
-
-
所有的命令和响应都是通过CMD线进行传输。
命令格式
所有的命令长度都是48bits。格式如下:

表格中的’x’表示,这些位的具体内容根据不同的命令填充不同的值。
一个命令总是由一个起始bit(固定为0)开始,跟在起始bit后面的是bit位表示传输的方向(host = 1)。
接下来的6个bit位表示命令的索引值,6个bit位最多支持64个命令。
有些命令需要参数,参数内容由32个bit位表示。所有的命令都有CRC校验功能。
命令分类
-
SD卡的命令集被分成了12类,见下图所示:
CCC: Card Command Class
-
命令分类实现
-
Class 0,2,4,5和8是所有的SD卡都必须支持的。
-
Class 7中除了CMD40以外,是SDHC和SDXC卡都必须支持的。
-
其他类别的命令都是可选实现。
详细的命令实现信息参见 « Physical_Specification» Table: Command Support Requirements。
-
-
SD卡的分类支持情况信息保存在CSD(card specific data)寄存器的CCC域内。提供给主机如何访问该卡的信息。
命令响应
-
所有的响应也是通过cmd线进行传输的。不同的响应的数据长度不同。
-
响应总是右一个起始bit位(固定为0)开始,跟在起始位后面的bit位表示传输方向(card = 0)。 除了R3,其他的所有响应都有CRC校验功能,所有的响应都是由一个结束bit位(固定为1)结尾。
-
响应分类
具体分类如下,其中R4和R5是SDIO中特有的。
-
R1(normal response command)

-
R1b
R1b is identical to R1 with an optional busy signal transmitted on data line. The card may become busy after receiving these commands based on its state prior to the command reception. The Host shall check for busy at the response.
-
R2(CID, CSD register)
用来响应CMD2和CMD10,返回CID寄存器的内容。 用来响应CMD9,返回CSD寄存器内容

响应中只传输了CID和CSD寄存器的[127…1]bits。寄存器中的bit0被响应的结束bit位取代。
-
R3(OCR register)
用来响应ACMD41,返回OCR寄存器的内容

-
R6(Published RCA response)
分配相对卡地址的响应
-
R7(Card interface condition)
响应CMD8,返回卡支持的电压信息。
-
R4(CMD5)
响应CMD5,并把OCR寄存器作为响应数据
-
R5(CMD52)
CMD52是一个读写寄存器的指令,R5用于CMD52的响应。
-
命令详细
Basic Commands
Block-Oriented Read Commands
Block-Oriented Write Commands
Block-Oriented Write Protection Commands
Erase Commands
Lock Card Commands
Application-Specific Commands
The following table describes all the application-specific commands supported/reserved by the SD Memory Card. All the following ACMDs shall be preceded with APP_CMD commands(CMD55).
I/O Mode Commands

Switch Function Commands
Function Extension Commands
-
-
C++ primer 读书笔记(九)--- 泛型算法
泛型算法概述
-
标准库并未给每个容器添加大量功能,而是提供了一组算法,这些算法的大多数都独立于任何特定的容器。这些算法是通用的(generic,或称泛型的):它们可以用于不同类型的容器和不同类型的元素。
-
大多数算法都定义在头文件algorithm中。标准库还在头文件numberic中定义了一组数值泛型算法。
-
通常情况下,这些算法并不直接操作容器,而是遍历由两个迭代器指定的一个元素范围来进行操作。算法遍历范围,对其中的每个元素进行一些处理。
-
虽然迭代器的使用令算法并不依赖于容器类型,但是大多数算法都使用了一个(或多个)元素类型上的操作(如==、< 、> 等)。不过大多数算法提供了一种方法,允许我们使用自定义的操作来代替默认的运算符。
-
泛型算法本身不会执行容器的操作,它们只会运行于迭代器智商,执行迭代器的操作。这种特性带来一个必要的编程假设:算法永远不会改变底层容器的大小。 算法可能改变容器中保存的元素的值,也可能在容器中移动元素,但永远不会直接添加或删除元素。
再探迭代器
-
除了为每个容器定义的迭代器之外,标准库还在头文件iterator中定义了额外几种迭代器,包括:
-
插入迭代器(insert iterator): 这些迭代器被绑定到一个容器上,可以用来向容器插入元素。
-
流迭代器(stream iterator): 这些迭代器被绑定到一个输入/输出流上,可以用来遍历所关联的IO流。
-
反向迭代器(reverse iterator): 这些迭代器向后而不是向前移动。除了forward_list之外的标注库容器都右反向迭代器。
-
移动迭代器(move iterator): 这些专用的迭代器不是拷贝其中的元素,而是移动它们。
-
插入迭代器
-
插入迭代器种类
-
back_inserter: 创建一个使用push_back的迭代器,it = back_inserter(c); 只有在容器类型支持push_back操作的情况下才能使用
-
front_inserter: 创建一个使用push_front的迭代器,it = front_inserter(c); 只有在容器类型支持push_front操作的情况下才能使用。
-
inserter: 创建一个使用insert的迭代器, it = inserter(c, iter); 第二个参数必须是一个指向c的迭代器。元素将被插入到iter迭代器所表示的元素之前。
-
-
插入迭代器操作
iter = value; 在iter指定的位置插入值value。 *it, ++it, –it 这些操作虽然存在,但是不会对it做任何事情。每个操作都返回it
iostream迭代器
-
虽然iostream类型不是容器,但是标准库定义了可用于这些IO类型对象的迭代器。
-
istream_iterator: 读取输入流, istream_iterator
t_iter(is); -
ostream_iterator: 向一个输入流写数据, ostream_iterator
t_iter(os);
-
-
istream_iterator
istream_iterator操作
istream_iterator<T> in(is); in_iter 从输入流is中读取类型为T的值 istream_iterator<T> in_eof; 读取类型为T的尾后迭代器 in1 == in2 in1 和 in2必须读取相同类型。如果它们都是尾后迭代器,或绑定到相同的输入,则两者相等 in1 != in2 同上 *in 返回从流中读取的值 in->mem 与(*in).mem的含义相同 ++in, in++ 使用元素类型所定义的»运算符从输入流中读取下一值 一个istream_iterator使用 » 来读取流,所以istream_iterator要读取的类型必须定义了输入运算符。
对于一个绑定到流的迭代器,一旦其关联的流遇到文件结尾或IO错误,迭代器的值就与尾后迭代器相等。
istream_iterator<int> in(cin), eof; // 从cin读取int vector<int> vec(in, eof); // 从迭代器范围构造vec, 从cin中读取int被用来构造vec当我们将一个istream_iterator绑定到一个流时,标准库并不保证迭代器立即从流读取数据。具体实现可以推迟读取数据,直到我们使用迭代器时才真正读取。 标准库保证的是,在我们第一次解引用迭代器之前,从流中读取数据的操作已经完成。
-
ostream_iterator
ostream_iterator操作
ostream_iterator<T> out(os); out将类型为T的值写到输出流os中 ostream_iterator<T> out(os, d); 每个值后面都输出一个d。d指向一个空字符结尾的字符数组 out = val 用 « 运算符将val写入到out所绑定的输出流中。val的类型必须与out可写的类型兼容 *out,++out,out++ 这些运算符是存在的,但是不对out做任何错误。每个运算符都返回out 运算符*和++实际上对ostream_iterator对象不做任何事情,因此忽略它们对程序没有任何影响,但是仍然推荐下面的写法。 这种写法中,流迭代器的使用与其他迭代器的使用保持一致。如果想要将此循环改成其他迭代器类型,修改起来很容易,且此循环的行为读起来更加清晰。
ostream_iterator<int> out_iter(cout, " "); for(auto e : vec) *out++ = e; // 赋值语句实际上将元素写到cout cout << endl; // 可以使用copy函数打印vec中的元素,这比写for循环更简单 copy(vec.cbegin(), vec.cend(), out_iter); cout << endl;可以为任何定义了输出运算符(«)的类型创建ostream_iterator对象。
反向迭代器
-
反向迭代器就是在容器中从尾元素向首元素反向移动的迭代器。对于反向迭代器,递增以及递减操作的含义是颠倒的。递增一个反向迭代器会移动到前一个元素,递减一个反向迭代器会移动到后一个元素。
-
除了forward_list以外,其他容器都支持反向迭代器。
-
通过调用reverse_iterator的base成员函数,可以将反向迭代器转换为普通迭代器。
-
从技术上讲,普通迭代器与反向迭代器的关系反映了左闭合区间的特性。关键点在于[line.crbegin(), rcomma) 和 [rcomma.base(), line.cend())指向line中相同的元素范围。为了实现这一点,rcomma和rcomma.base()必须生成相邻位置而不是相同位置, crbegin()和cend()也是如此
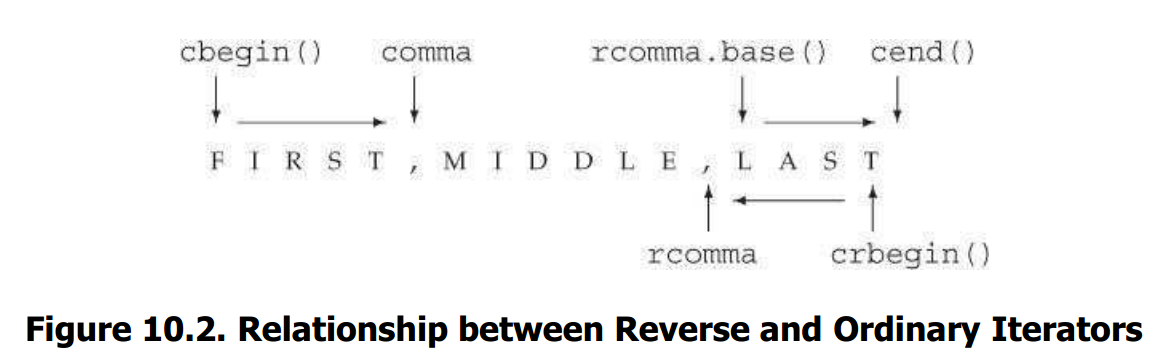
// 在一个逗号分割的列表中查找第一个元素 // line: FIRST,MIDDLE,LAST auto comma = find(line.cbegin(), line.cend(), ','); cout << string(line.cbegin(), comma) << endl; // 查找最后一个元素 auto rcomma = find(line.crbegin(), line.crend(), ','); // 逆序输出单词的字符 : TSAL cout << string(line.crbegin(), rcomma) << endl; // 正序输出单词的字符: LAST cout << string(rcomma.base(), line.cend()) << endl;
根据算法要求的迭代器操作进行的迭代器类别划分
-
任何算法的最基本的特征是它要求其迭代器提供哪些操作。算法所要求的迭代器操作可以分为5个迭代器类别(iterator category)。
输入迭代器 只读,不写;单边扫描,只能递增 输出迭代器 只写,不读;单遍扫描,只能递增 前向迭代器 可读写;多遍扫描,只能递增 双向迭代器 可读写;多遍扫描,可递增递减 随机访问迭代器 可读写,多遍扫描,支持全部迭代器器运算 除了输出迭代器之外,一个高层类别的迭代器支持底层类别迭代器的所有操作。
C++标准指明了泛型和数值算法的每个迭代器参数的最小类别。对每个迭代器参数来说,其能力必须与规定的最小类别至少相当。向算法传递一个能力更差的迭代器会产生错误。
-
输入迭代器
可以读取序列中的元素,一个输入迭代器必须支持
- 用于比较两个迭代器的相等和不相等运算符(== !=)
- 用于推进迭代器的前置和后置递增运算(++)
- 用于读取元素的解引用运算符(*);解引用只会出现再赋值运算符的右侧
- 箭头运算符(->),等价于(*it).member,即,解引用迭代器,并提取对象的成员
输入迭代器只用于顺序访问。只能用于单遍扫描算法。
算法find和accumulate要求输入迭代器;而istream_iterator是一种输入迭代器。
-
输出迭代器
可以看做输入迭代器功能上的补集 — 只写不读。输出迭代器必须支持
- 用于推进迭代器的前置和后置递增运算(++)
- 解引用运算符(*),只出现在赋值运算符的左侧
输出迭代器只能用于单遍扫描算法。用作目的位置的迭代器通常都是输出迭代器。例如,copy函数的第三个参数就是输出迭代器。
ostream_iterator是一种输出迭代器。
-
前向迭代器
- 支持输入和输出迭代器的所有操作,而且可以多次读写同一个元素。
- 只能在序列中沿一个方向移动。
算法replace要求前向迭代器。
forward_list容器上的迭代器是前向迭代器。
-
双向迭代器
- 可以正向/反向读写序列中的元素。
- 支持前向迭代器中所有操作。
- 还支持前置和后置的递减运算符(–).
算法reverse要求双向迭代器。
除了forward_list之外,其他标准库容器上的迭代器都是双向迭代器。
-
随机访问迭代器
- 提供在常量时间内访问序列中任意元素的能力。
- 支持双向迭代器的所有功能。
- 支持比较两个迭代器的关系运算符(< <= > >=)
- 迭代器和一个整数的加减运算(+ += - -=)
- 用于两个迭代器上的减法运算符(-),得到两个迭代器的距离
- 下标运算符(iter[n]),与*(iter[n])等价
算法sort要求随机访问迭代器。
array、deque、string和vector的迭代器都是随机访问迭代器,用于访问内置数组元素的指针也是。
谓词
-
谓词是一个可调用的表达式,其返回结果是一个能用作条件的值。标准库算法所使用的谓词分为两类:
- 一元谓词(unary predicate): 只接受单一参数
- 二元谓词(binary predicate): 接受两个参数
-
接受谓词参数的算法对输入序列中的元素调用谓词。因此,元素类型必须能转换为谓词的参数类型。
-
根据算法接受一元还是二元谓词,我们传递给算法的谓词必须严格接受一个或两个参数。但是,有时我们希望进行的操作需要更多的参数,超出了算法对谓词的限制。 为了解决此问题,需要使用另外一些语言特性,如lambda表达式和bind参数绑定。
lambda表达式
可调用对象
-
我们可以向一个算法传递任何类别的可调用对象(callable object)。
-
对于一个对象或一个表达式,如果可以对其使用调用运算符,则称它为可调用的。 即,如果e是一个可调用的表达式,则我们可以编写代码e(args),其中args是一个逗号分割的一个或多个参数的列表。
-
可调用对象的种类有:
- 函数
- 函数指针
- 重载了函数调用运算符的类
- lambda表达式
lambda简介
-
一个lambda表达式表示一个可调用的代码单元。可以将其理解为一个未命名的内联函数。与任何函数类似,一个lambda具有一个返回类型、一个参数列表和一个函数体。 与函数不同,lambda可能定义在函数内部。
-
lambda表达式的形式
[capture list] (parameter list) -> return type { function body }
capture list,捕获列表,是一个lambda所在函数中定义的局部变量的列表(通常为空) return type、parameter list 和 function body与任何普通函数一样,分别表示返回类型、参数列表和函数体。与普通函数不同的时,lambda必须使用尾置返回来指定返回类型。
参数列表和返回类型是可选的。捕获列表和函数体是必选的。 如果忽略返回类型,lambda根据函数体中的代码推断出返回类型。如果函数体只是一个return语句,则返回类型从返回的表达式的类型推断而来。否则,返回类型为void。
auto f = [] { return 32; }; cout << f() << endl; // 打印32 -
对于那种只在一两个地方使用的简单操作,lambda表达式是最有用的。 如果我们需要在很多地方使用相同的操作,通常应该定义一个函数,而不是多次编写相同的lambda表达式。 类似地,如果一个操作需要很多语句才能完成,通常使用函数更好。
如果lambda的捕获列表为空,通常可以用函数来替代它。但是,对于需要捕获局部变量的lambda,用函数来替代它就不是那么容易了。
向lambda传递参数
-
与普通参数不同的是,lambda不能有默认参数。因此,一个lambda调用实参数目永远与形参数目相等。
//按长度排序,长度相等的单词维持字典序 stable_sort(words.begin(), words.end(), [](const string &a, const string &b) { return a.size() < b.size(); } );当stable_sort需要比较两个元素时,它就会调用给定的lambda表达式。
lambda捕获列表
-
当定义一个lambda时,编译器生成一个与lambda对应的新的(未命名的)类类型。可以这样理解,当向一个函数传递一个lambda时,同时定义了一个新类型和该类型的对象:传递的参数就是此编译器生成的类类型的未命名对象。 类似的,当使用auto定义一个用lambda初始化的变量时,定义了一个从lambda生成的类型的对象。
默认情况下,从lambda生成的类包含一个对应该lambda所捕获的变量的数据成员。类似任何普通类的数据成员,lambda的数据成员也在lambda对象创建时被初始化。
-
值捕获
与传值参数类似,采用值捕获的前提是变量可以拷贝。与参数不同,被捕获的变量的值是在lambda创建是拷贝,而不是调用是拷贝。
void fcn1() { size_t v1 = 32; // 局部变量 // 将v1拷贝到名为f的可调用对象 auto f = [v1]{return v1;}; v1 = 0; auto j = f(); // j为32;f保存了我们创建它时v1的拷贝 auto f2 = [v1] () mutable { return ++v1; }; auto k = f2(); // k = 1 }默认情况下,对于一个值拷贝的捕获变量,lambda不会改变其值。如果我们希望改变它时,就必须在参数列表后面加关键字mutable。
-
引用捕获
一个以引用方式捕获的变量与其他任何类型的引用的行为类似。当我们在lambda函数体内使用此变量时,实际上使用的是引用所绑定的对象。
void fcn2() { size_t v1 = 32; auto f2 = [&v1] { return v1; }; auto f3 = [&v1] { return ++v1; }; v1 = 0; auto j = f2(); // j = 0, f2保存v1的引用而非拷贝 auto k = f3(); // j = 1, }当使用引用方式捕获一个变量时,必须保证在lambda执行时变量是存在的。
一个引用捕获的变量是否可以修改,依赖于此引用指向的是一个const类型还是一个非const类型。
一般情况下,应该尽量减少捕获的数据量,来避免潜在的捕获导致的问题。而且,如果可能的话,应该避免捕获指针或引用。
-
隐式捕获
可以让编译器根据lambda体中的代码来推断我们需要使用哪些变量。为了指示编译器推断捕获列表,应在捕获列表中写一个&或=。 & 告诉编译器采用引用捕获方式 = 告诉编译器采用值捕获方式
如果我们希望对一部分变量采用值捕获,对其他变量采用引用捕获,可以混合使用隐式捕获和显示捕获:
void biggies(vector<string> &words, vector<string>::size_type sz, ostream &os = cout, char c = ' ') { //os 隐式捕获,引用捕获方式;c显示捕获,值捕获方式 for_each(words.begin(), words.end(), [&, c](const string &s) { os << s << c; } ); //os 显示捕获,引用捕获方式;c隐式捕获,值捕获方式 for_each(words.begin(), words.end(), [=, &os](const string &s) { os << s << c; } ); }当混合使用隐式捕获和显示捕获时,捕获列表中的第一个元素必须是一个 & 或 =。此复合指定了默认捕获方式为引用或值。
当混合使用隐式捕获和显示捕获时,显示捕获的变量必须使用隐式捕获不同的方式。即,如果隐式捕获是引用方式,则显示捕获必须采用值方式。
lambda返回类型
默认情况下,如果一个lambda体包含return之外的任何语句,则编译器假定此lambda返回void。与其他返回void的函数类似,被推断返回void的lambda不能返回值。
// 正确 transform(vi.begin(), vi.end(), vi.begin(), [] (int i) { return i < 0 ? -i : i; }); // 错误,不能推断lambda的返回类型 transform(vi.begin(), vi.end(), vi.begin(), [] (int i) { if (i<0) return -i; else return i; }); // 正确 transform(vi.begin(), vi.end(), vi.begin(), [] (int i) -> int { if(i<0) return -i; else return i; });bind与参数绑定
-
很多地方都会使用,且需要捕获局部变量的lambda表达式。不能用普通的函数替代。此时可以使用bind标准库函数。它定义在#include
头文件中。 可以将bind函数看做一个通用的函数适配器,它接受一个可调用对象,生成一个新的可调用对象来“适应”原对象的参数列表。
调用bind的一般形式
-
一般形式为
auto newCallable = bind(callable, arg_list);newCallable 本身是一个可调用对象, arg_list 是一个逗号分割的参数列表,对应给定的callable参数。 即,当我们调用newCallable时,newCallable会调用callable,并传递给它arg_list中的参数。
arg_list中的参数可能包含形如_n的名字,其中n是一个整数。这些参数是“占位符”,表示newCallable的参数: _1 为newCallable的第一个参数,_2为newCallable的第二个参数,依次类推。 名字_n都定义在placeholders的命名空间中,而这个命名空间本身定义在std命名空间中。为了使用这些_1,_2的名字,需要声明
using namespace std::placeholders; bool check_size(const string &s, string::size_type sz); auto check6 = bind(check_size, _1, 6); // 使用lambda方式 auto wc = find_if(words.begin(), words.end(), [sz](const string &s) { return s.size() > sz;}); // 使用bind方式 auto wc = find_if(words.begin(), words.end(), bind(check_size, _1, sz));
使用bind重排参数顺序
-
可以使用bind绑定给定可调用对象中的参数或重新安排其顺序。例如,假定f是一个可调用对象,有5个参数
// g是一个有两个参数的可调用对象 auto g = bind(f, a, b, _2, c, _1); g(x, y); // 等价于f(a, b, y, c, x); -
绑定引用参数
默认情况下,bind的那些不是占位符的参数被拷贝到bind返回的可调用对象中。如果我们希望使用引用方式传递时,需要使用ref()或cref()。 ref 函数返回一个对象,包含给定的引用,此对象是可以拷贝的。 cref函数,生成一个保存const引用的类。 ref和cref也定义在头文件functional中。
ostream& print(ostrem& os, const string& s, char c) { return os << s << c; } // lambda 版本实现 for_each(words.begin(), words.end(), [&os, c](const string& s) { os << s << c; }); // 错误的bind版本,不能拷贝os for_each(words.begin(), words.end(), bind(print, os, _1, c)); // 正确的bind版本 for_each(words.beging(), words.end(), bind(print, ref(os), _1, c));
泛型算法规则
算法形参模式
算法命名规范
特定容器算法
常用算法说明
-
-
C++ primer读书笔记(八)--- Containers
顺序容器(sequential container)为程序员提供了控制元素存储和访问顺序的能力。元素在顺序容器中的顺序与其加入容器时的位置相对应。
关联容器中元素的位置由元素相关联的关键字值决定。
所有容器类都共享公共的接口,不同容器按不同方式对其扩展。这个公共接口使容器的学习更加容易—基于某种容器所学习的内容也都适用于其他容器。每种容器都提供了不同的性能和功能的权衡。
容器公共特性
容器库概述
-
一般来说,每个容器都定义在一个头文件中,文件名与类型名相同。即,deque定义在头文件deque中,list定义在头文件list中,以此类推。
-
容器均定义为模板类。对大多数,但不是所有容器,还需要额外提供元素类型信息,如对于vector,必须提供额外信息来生成特定的容器类型:
list<Sales_data> // 保存Sales_data对象的list deque<double> // 保存double的deque -
可以在容器中保存几乎任何类型,但某些容器操作对元素类型有其自己的特殊要求,这时,定义的容器就无法执行这些容器操作。 例如,顺序容器构造函数的一个版本接收容器大小参数,它使用了容器元素类型的默认构造函数。但某些类没有默认构造函数时,我们在构造这种元素类型的容器时,就不能使用该构造函数。
// 假定 noDefault 是一个没有默认构造函数的类型 vector<noDefault> v1(10, init); // 正确:提供了元素初始化器 vector<noDefault> v2(10); // 错误:必须提供一个元素初始化器
迭代器
-
与容器一样,迭代器有着公共的接口: 如果一个迭代器提供某个操作,那么所有提供相同操作的迭代器对这个操作的实现方式都是相同的。例如,标准容器类型上的所有迭代器都允许我们访问容器中的元素,而所有迭代器都是通过解引用运算符来实现这个操作的。类似的,标准容器的所有迭代器都提供了递增运算符,从当前元素移动到下一元素。
-
标准容器迭代器的运算符
*iter 返回迭代器iter所指向元素的引用 iter->mem 解引用iter并获取该元素的名为mem的成员,等价于(*iter).mem ++iter 令iter指向容器的下一个元素 - -iter 令iter指向容器的上一个元素 iter1 == iter2 判断两个容器是否相等 iter1 != iter2 判断两个容器是否不相等 如果两个迭代器指示的是同一个元素或者是同一个容器的尾后迭代器,则相等;反之,不相等
forward_list的迭代器不支持递减运算符(- -)
执行解引用的迭代器必须合法并确实指示着某个元素。试图解引用一个非法迭代器或者尾后迭代器都是未被定义的行为。
-
迭代器支持的算术运算
iter + n 结果仍是一个迭代器,结果迭代器指示的位置与iter相比向前移动了n个元素。结果迭代器或者指示容器内的第一个元素,或者指示容器尾元素的下一位置 iter - n 结果仍是一个迭代器,结果迭代器指示的位置与iter相比向后移动了n个元素。结果迭代器或者指示容器内的第一个元素,或者指示容器尾元素的下一位置 iter1 += n 迭代器加法的复合赋值语句,将iter1加n的结果赋给iter1 iter1 -= n 迭代器减法的复合赋值语句,将iter1减n的结果赋给iter1 iter1 - iter2 两个迭代器相减的结果是它们之间的距离。参与运算的两个迭代器必须指向的是同一个容器 > >= < <= 如果某个迭代器指向的容器位置在另一个迭代器所指向位置之前,则说前者小于后者。参与运算的两个迭代器必须指向的是同一个容器 上述的运算只能用于string、vector、deque和array的迭代器。不能将它们用于其他任何容器类型的迭代器。
-
获取迭代器
c.begin() c.end() 返回指向容器c的首元素和尾元素之后位置的迭代器 c.cbegin() c.cend() 返回const_iterator c.rbegin() c.rend() 返回指向容器c的尾元素和首元素之前位置的迭代器 c.crbegin() c.crend() 返回const_reverse_iterator 反向迭代器不支持forward_list
一个迭代器范围(iterator range)由一对迭代器表示,它是一个左闭合区间 [begin, end),表示范围自begin开始,于end之前(不包括end)结束。 其中begin和end必须满足下面两个条件: 1)它们指向同一个容器中的元素,或者是容器最后一个元素之后的位置。 2)end可以与begin指向相同的位置,但不能指向begin之前的位置,即可以通过反复递增begin来到达end
因为end()操作返回的迭代器并不实际指向某个元素,所以不能对其进行递增或解引用操作。
不以c开头的函数都是被重载过的。也就是说,实际上有两个名为begin/rbegin的成员。以c开头的版本是C++11新标准引入的,用于支持auto与begin和end函数的结合使用。
// 显示指定类型 list<string>::iterator it5 = a.begin(); list<string>::const_iterator it6 = a.begin(); // 是iterator还是const_iterator依赖与a的类型 auto it7 = a.begin(); // 仅当a是const时,it7是const_iterator auto it8 = a.cbegin(); // it8是const_iterator当auto与begin或end结合使用时,获得的迭代器类型依赖于容器类型。但以c开头的版本还是可以获得const_iterator的,而不管容器的类型是什么。
容器类型成员
-
类型成员信息见下表
iterator 此容器类型的迭代器类型 const_iterator 可以读取元素,但不能修改元素的迭代器类型 size_type 无符号整数类型,足够保存此种容器类型最大可能容器的大小 difference_type 带符号整数类型,足够保存两个迭代器之间的距离 value_type 元素类型 reference 元素的左值类型: 与value_type&含义相同 const_reference 元素的const左值类型(即 const value_type& ) reverse_iterator 按逆序寻址元素的迭代器 const_reverse_iterator 不能修改元素的逆序迭代器 反向迭代器 reverse_iterator 和 const_reverse_iterator 不支持forward_list容器。它是一种反向遍历容器的迭代器,与正向迭代器相比,各种操作的含义都发生了颠倒。例如,对一个反向迭代器执行++操作,会得到上一个元素。
通过value_type、reference和const_reference,可以在不了解容器中元素类型的情况下使用它。如果需要元素类型,可以使用容器的value_type。如果需要元素的一个引用,可以使用reference或const_reference。这些元素相关的类型别名在泛型编程中非常有用。
-
容器类型成员使用举例:
list<string>::iterator iter; vector<int>::difference_type count;
容器定义和初始化
-
容器定义和初始化操作
操作 描述 array容器附加要求 C c; 默认构造函数。 c中元素按默认方式初始化。 C c1(c2) c1初始化为c2的拷贝。c1和c2必须是相同类型 两个相同类型且相同大小 C c1 = c2 同上 同上 C c{a,b,c…} c初始化为初始化列表中的元素的拷贝。列表中元素类型必须与c的元素类型相容 列表中元素数目必须等于或小于array的大小,任何遗漏的元素都进行值初始化 C c={a,b,c…} 同上 同上 C c(b,e) c初始化为迭代器b和e指定范围中的元素拷贝。范围中元素的类型必须与C的元素类型相容 array不支持 每个容器类型都定义了一个默认构造函数。除array之外,其他容器的默认构造函数都会创建一个指定类型的空容器。
对于除array之外的容器,使用列表初始化方式进行初始化时,隐含的指定了容器的大小: 容器将包含与初始值一样多的元素。
c1 和 c2 必须是相同类型容器要求: 它们必须是相同的容器类型 且 保存的是相同的元素类型。
元素类型相容指,只要能将要拷贝的元素转换为要初始化的容器的元素类型即可。
-
代码举例:
// 每个容器有三个元素,用给定的初始化器进行初始化 list<string> authors = {"Milton", "Shakespeare", "Austen"}; vector<const char*> articles = {"a", "an", "the"}; list<string> list2(authors); // 正确: 类型匹配 deque<string> deque1(authors); // 错误: 容器类型不匹配 vector<string> vector1(articles); // 错误: 容器元素类型不匹配 // 正确: 可以将const char* 转换为string forward_list<string> words(articles.begin(), articles.end()); // 正确: 拷贝元素,直到(但不包括)it指向的元素 (假设it表示authors中的一个元素) deque<string> authList(authors.begin(), it); array<int, 32> a1; // 类型为 保存32个int的数组 array<string, 10> a2; // 类型为 保存10个string的数组 array<int, 10>::size_type i; // 正确 array<int>::size_type j; // 错误: array<int> 不是一个类型
容器赋值和swap
-
操作列表
操作 描述 array附加情况 c1 = c2 将c1中的元素替换为c2中元素的拷贝。c1和c2必须具有相同的类型 无 c = {a,b,c…} 将c中元素替换为初始化列表中元素的拷贝 不支持 swap(c1, c2) c1和c2必须具有相同的类型。swap通常比从c2向c1拷贝元素快的多 交换两个array所需时间与array中元素的数量成正比 c1.swap(c2) 同上 同上 -
赋值运算符将其左边容器中的全部元素替换为右边容器中元素的拷贝。赋值相关运算会导致左边容器内部的迭代器、指针和引用失效。
-
swap操作交换两个相同类型容器的内容。swap操作不会导致指向容器的迭代器、引用和指针失效(容器类型array和string的情况除外)。
除array外,swap不会对任何元素进行拷贝、删除或插入操作,交换的两个容器内的元素本身并为交换,swap操作指示交换了两个容器的内部数据结构。 而对于array容器,swap操作会真正交换它们的元素,因此,交换两个array容器所需时间与array中元素的数目成正比。
除string和array外,指向容器的迭代器、引用和指针在swap操作后不会失效,。它们仍指向swap操作之前所指向的那些元素。但是,在swap之后,这些元素已经属于不同的容器了。 对与string调用swap,会导致迭代器、引用和指针失效。 对于array,在swap之后,指针、引用和迭代器所绑定的元素保持不变,但是元素值已经与另外一个array中对应元素的值进行了交换。
在C++11新标准中,容器即提供了成员函数版本的swap,也提供了非成员函数版本的swap。 而早期标准库只提供了成员函数版本。 非成员版本的swap在泛型编程中是非常重要的,因此,统一使用非成员版本的swap是一个好习惯。
-
代码举例:
c1 = c2; // 将c1的内容替换为c2中元素的拷贝 c1 = {1, 2, 3}; // 赋值后,c1大小为3 array<int, 10> a1 = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}; array<int, 10> a2 = {0}; // 所有元素都为0 a1 = a2; // 替换a1中的元素 a2 = {0}; // 错误: 不能将一个花括号列表赋予数组 vector<string> sv1(10); vector<string> sv2(20); vector<string>::iterator it1 = sv1.begin() + 3; // it1 指向sv1[3]的string swap(sv1, sv2); // it1 指向sv2[3]的元素
容器关系运算
-
容器关系运算操作
== != 所有容器都支持相等(不相等)操作 < <= > >= 无序关联容器不支持 关系运算符左右两边的运算对象必须是相同类型的容器,且必须保存相同类型的元素。
-
关系运算规则
- 如果两个容器具有相同大小且所有元素都两两对应相等,则这两个容器相等;否则,两个容器不等。
- 如果两个容器大小不同,但较小容器中每个元素都等于较大容器中的对应元素,则较小容器小于较大容器。
- 如果两个容器都不是另外一个容器的前缀子序列,则它们的比较结果取决于第一个不相等的元素的比较结果。
-
容器的关系运算符使用元素的关系运算符完成比较
只有当元素类型定义了相应的关系运算符时,我们才可以使用关系运算符来比较两个容器。
-
代码举例:
vector<int> v1 = {1, 3, 5, 7, 9 12}; vector<int> v2 = {1, 3, 9}; vector<int> v3 = {1, 3, 5, 7}; vector<int> v4 = {1, 3, 5, 7, 9, 12}; v1 < v2; // true v1 < v3; // false v1 == v4; // true v1 == v2; // false vector<Sales_data> storA, storB; // 假设Sales_data类中没有定义 < 运算符操作 if(storA > storB) ... // 错误操作
容器大小
-
容器大小操作
操作 描述 特殊说明 c.size() c中元素的数目 forward_list不支持该操作 c.max_size() c可保存的最大元素数目 c.empty() 若c中存储了元素,返回false,否则返回true
容器添加/删除元素
-
相关操作
c.insert(args) 将args中的元素拷贝进c c.emplace(inits) 使用inits参数构造c中的一个元素 c.erase(args) 删除args指定的元素 c.clear() 删除c中的所有元素,返回void 这些操作不适用于array容器
在不同的容器中,这些操作的接口都不同
顺序容器
顺序容器类型
- 下表列出了标准库中的顺序容器,所有顺序容器都提供了快速顺序访问元素的能力。但是这些容器在以下方面都有不同的性能折中。
- 向容器中添加或从容器中删除元素的代价
- 非顺序访问容器中元素的代价
类型 描述 添加删除元素操作 元素访问方式 尾部插入删除元素 头部插入删除元素 其他位置插入删除元素 array 固定大小数组 X 快速随机访问 X X X vector 可变大小数组 支持 快速随机访问 快速 可能很慢 可能很慢 string 与vector类似的容器,专门用于保存字符 支持 快速随机访问 快速 可能很慢 可能很慢 list 双向链表 支持 双向顺序访问 快速 快速 快速 forward_list 单向链表 支持 单向顺序访问 快速 快速 快速 deque 双端队列 支持 快速随机访问 快速 快速 可能很慢 现代C++程序应该使用标准库容器,而不是更原始的数据结构,如内置数组。
- 顺序容器选择原则
- 除非你有很好的理由选择其他容器,否则应使用vector。
- 如果你的程序有很多小的元素,且空间的额外开销很重要,则不要使用list或forward_list。
- 如果程序要求随机访问元素,应使用vector或deque。
- 如果程序要求在容器的中间位置插入或删除元素,应使用list或forward_list。
- 如果程序要求在头尾位置插入或删除元素,但不会在中间位置进行插入或删除操作,则使用deque。
- 如果程序只有在读取输入时才需要在容器的中间位置插入元素,随后需要随机访问元素
- 首先,确认是否真的需要在容器中间插入元素。当处理输入数据时,通常可以很容易的向vector追加数据,然后调用标准库的sort函数来重排容器中的元素,从而避免在中间位置添加元素。
- 如果必须在中间位置插入元素,考虑在输入时使用list,一旦输入完成,将list中的内容拷贝到一个vector中。
如果程序中既需要随机访问元素,又要在容器中间位置插入元素,容器选择取决于 在list或forward_list中访问元素与vector或deque中插入/删除元素的相对性能。一般来说,应用中占主导地位的操作决定了容器类型的选择。在此情况下,对两种容器分别测试应用性能可能就是必须的了。
如果不确定使用哪种容器,可以在程序中只使用vector和list公共的操作:使用迭代器,不使用下标操作,避免随机访问。这样,在必要时选择使用vector或list都很方便。
-
-
C++ primer读书笔记(七)--- IO Library
IO库类型和头文件
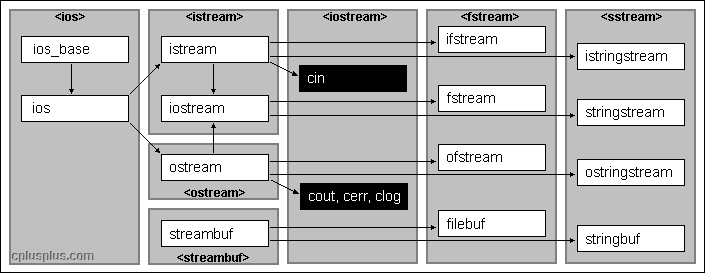
- 为了支持不同种类的IO操作,在iostream之外,标准库还定义了其他一些IO类型。
- iostream 定义了用于读写流的基本类型
- fstream 定义了读写命名文件的类型
- sstream 定义了读写内存string对象的类型
为了支持宽字符语言,标准库还定义了一组类型和对象来操作wchar_t类型的数据。宽字符的版本的类型和函数的名字以一个w开始。
—–表1—–
头文件 类型 说明 iostream istream,wistream 从流读取数据 ostream,wostream 向流写入数据 iostream,wiostream 读写流 fstream ifstream,wifstream 从文件读取数据 ofstream,wofstream 向文件写入数据 fstream,wfstream 读写文件 sstream istringstream,wistringstream 从string读取数据 ostringstream,wostringstream 向string写入数据 stringstream,wstringstream 读写string
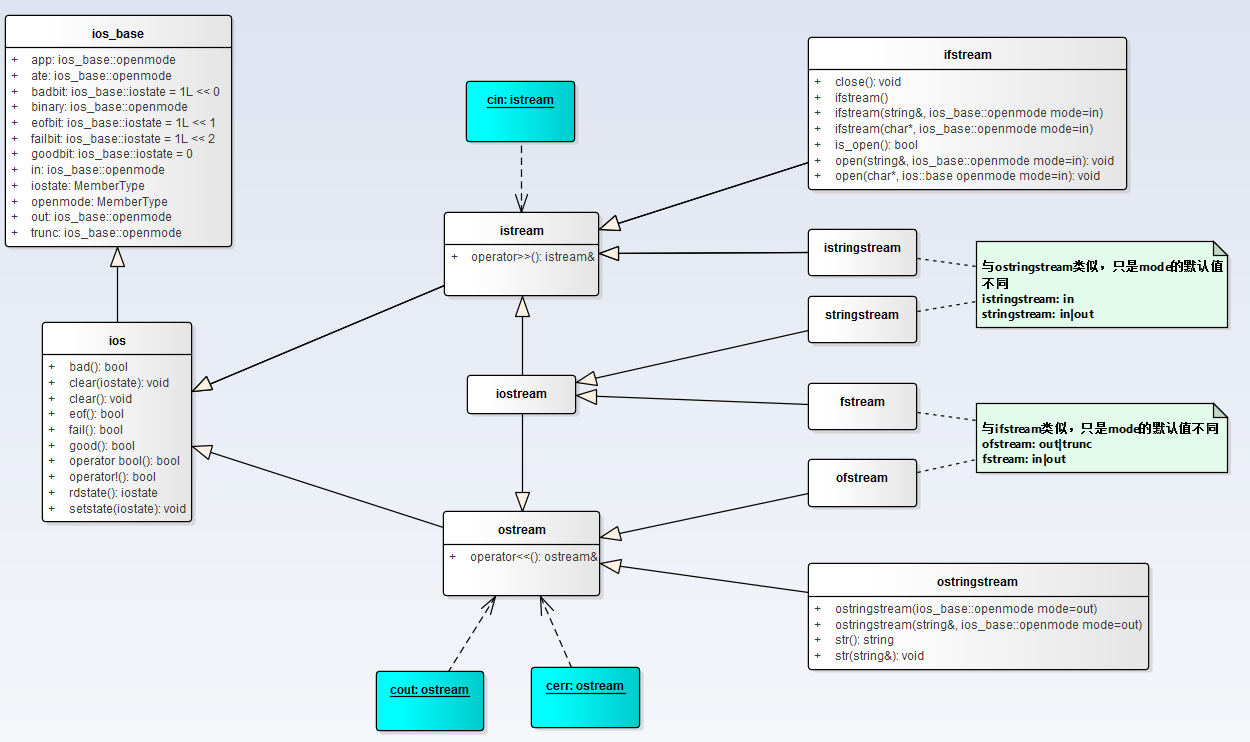
IO库之间的关系
继承关系如下图
公共特性
下面所描述的标准库流特性可以无差别的应用与普通流、文件流和string流,以及char或宽字符流版本。
-
不能拷贝或对IO对象赋值,也不能将形参或返回类型设置为流类型。
进行IO操作的函数通常以引用方式传递和返回流。读写一个IO对象会改变其状态,因此传递和返回的引用不能是const的。
ofstream out1, out2; out1 = out2; // 错误:不能对流对象赋值 ofstream print(ofstream); // 错误:不能初始化ofstream参数 out2 = print(out2); // 错误:不能拷贝流对象 -
IO库条件状态
下面表格中的strm是一种IO类型,在<表1>中已经列出。
成员 描述 strm::iostate iostate是一种机器相关的类型,提供了表达条件状态的完整功能 strm::badbit 用来指出流已经崩溃 strm::failbit 用来指出一个IO操作失败了 strm::eofbit 指出流到达了文件结束 strm::goodbit 用来指出流未处于错误状态。此值保证为零 s.eof() 若流s的eofbit置位,则返回true s.fail() 若流s的failbit或badbit置位,则返回true s.bad() 若流s的badbit置位,则返回true s.good() 若流s处于有效状态(eofbit/failbit/badbit均未被置位),则返回true s.clear() 将流s中所有条件状态复位,即将流的状态设置为有效,返回void s.clear(flags) 根据给定的flags标志位,将流s中对应条件状态复位。flags的类型为strm::iostate。返回void s.setstate(flags) 根据给定的flags标志位,将流s中对应条件状态置位。flags的类型为strm::iostate。返回void s.rdstate() 返回流s的当前条件状态,返回类型为strm::iostate 只有当一个流处于无错状态时,才可以从它读取数据或向它写入数据。一旦流发生错误,其上后续的IO操作都会失败。
由于流可能处于错误状态,因此在使用一个流之前应检查其是否处于良好状态。
while(cin >> word) // OK: 读操作成功......ios中operator bool运算符操作的返回值的定义为:
- true if none of failbit or badbit is set.
- false otherwise.
到达文件结束位置,eofbit和failbit都会被置位。
-
输出缓冲
每个输出流都管理一个缓冲区,用于保存程序读写的数据。
导致缓冲刷新(即,数据真正写到输出设备或文件)的原因有:
- 程序正常结束,作为main函数的return操作的一部分,缓冲刷新被执行。
- 缓冲区满时,需要刷新缓冲,而后新的数据才能继续写入缓冲区。
- 可以使用操作符endl来显示刷新缓冲区。
- 使用操纵符unitbuf设置流的内部状态,所有输出操作后都会立即刷新缓冲区。默认情况下,对cerr是设置unitbuf的,因此写入cerr的内容都是立即刷新的。
- 一个流可以被关联到另一个流。当读写被关联的流时,关联到的流的缓冲区会被刷新。例如,默认情况下,cin和cerr都关联到cout,因此读cin或写cerr时都会导致cout的缓冲区被刷新。
操纵符使用举例:
cout << "hi!" << endl; // 输出hi和一个换行符,然后刷新缓冲区 cout << "hi!" << flush; // 输出hi,然后刷新缓冲区,不附加任何额外字符 cout << "hi!" << ends; // 输出hi和一个空字符,然后刷新缓冲区 cout << unitbuf; // 所有输出操作后都会立即刷新缓冲区 // 任何输出都立即刷新,无缓冲 cout << nounitbuf; // 回到正常的缓冲方式如果程序异常终止,输出缓冲区是不会被刷新的。当一个程序崩溃后,它所输出的数据很有可能停留在输出缓冲区中等待打印。
文件输入输出
-
fstream特有的操作
下表中的fstream是头文件fstream中定义的一个类型。
fstream fstrm; 创建一个未绑定的文件流。 fstream fstrm(s); 创建一个fstream,并打开名为s的文件。s可以是string类型,也可以是一个char*。这种构造函数是explicit的。默认的文件模式mode依赖于fstream的类型 fstream fstrm(s, mode); 与上一个构造函数类似,但按照指定mode打开文件 fstrm.open(s) 打开名为s的文件,并将文件与fstrm绑定。s可以是string类型也可以是一个char*。默认文件mode依赖于fstream的类型。 fstrm.close() 关闭与fstream绑定的文件。返回void fstrm.is_open() 返回一个bool。指出与fstrm关联的文件是否成功打开且尚未关闭。 -
创建文件流对象时,可以提供文件名,此时,open会自动被调用。如果没有提供文件名,则需要调用open来将该流对象与文件关联起来,如果调用open失败,failbit会被置位。
-
一旦一个文件流已经打开,它就保持与对应文件的关联。对一个已经打开的文件流调用open会失败,并会导致failbit被置位。随后的试图使用文件流的操作都会失败。为了将文件流关联到另一个文件,必须首先关闭已经关联的文件。
-
当一个fstream对象被销毁时,close会被自动调用。
-
在C++11标准中,文件名既可以是string类型对象,也可以是C风格字符数组。旧版本中标准库只允许C风格字符数组。
-
文件打开模式
模式 描述 in 以读方式打开 out 以写方式打开 app 每次写操作前均定位到文件末尾(追加写) ate 打开文件后立即定位到文件末尾 trunc 截断文件 binary 以二进制方式进行IO 指定文件模式有如下限制:
- 只可以对ofstream和fstream对象设定out模式
- 只可以对ifstream和fstream对象设定in模式
- 只有当out也被设定时才可以设定trunc模式
- 只要trunc模式没被设定,就可以设定app模式。在app模式下,即是没有显示指定out模式,文件也总是以out模式被打开
- 默认情况下,即是我们没有指定trunc,以out模式打开的文件也会被截断。为了保留以out模式打开的文件内容,必须同时指定app模式或者同时指定in模式
- ate和binary模式可用于任何类型的文件流对象,且可以与其他任何文件模式组合使用。
out模式打开文件举例(以open方式打开文件相同):
ofstream out("file1"); //隐含以输出模式打开文件并截断文件 ofstream out2("file1", ofstream::out); //隐含的截断文件 ofstream out3("file1", ofstream::out|ofstream::trunc); //为了保留文件内容,必须显示指定app模式 ofstream out4("file1", ofstream::app); //隐含为输出模式 ofstream out5("file1", ofstream::out|ofstream::app);
string流
-
stringstream特有的操作
下表中的sstream是头文件sstream中定义的一个类型。
sstream strm; 定义一个未绑定的stringstream对象。 sstream strm(s); 定义一个sstream对象,保存string s的一个拷贝。此构造函数是explicit的。 strm.str() 返回strm所保存的string的拷贝 strm.str(s) 将string s拷贝到strm中,返回void
- 为了支持不同种类的IO操作,在iostream之外,标准库还定义了其他一些IO类型。