- 参考资料
- 相关概念
- Node->Socket->Core->Processor
- Node信息查询
- Socket信息查询
- Core信息查询
- processor信息查询
- sysfs中cpu信息说明
- CPU热拔插
参考资料
- linux-4.4.23/Documentation/cputopology.txt
- linux-4.4.23/Documentation/cpu-hotplug.txt
- 玩转CPU Topology
- 团子的小窝
- 秦白衣的技术专栏
相关概念
-
NUMA
Non-Uniform memory access is a computer memory design used in multiprocessing, where the memory access time depends on the memory location relative to the processor. Under NUMA, a processor can access its own local memory faster than non-local memory (memory local to another processor or memory shared between processors). The benefits of NUMA are limited to particular workloads, notably on servers where the data are often associated strongly with certain tasks or users. NUMA architectures logically follow in scaling from symmetric multiprocessing (SMP) architectures.
NUMA 是一种为多处理器设计的非一致性内存访问方式,内存存取时间依赖于内存相对于处理器的位置。 在NUMA中,处理器访问它自己本地的内存速度比访问非本地内存(另一个处理器对应的本地内存或多个处理器共享的内存)要快的多。 NUMA的优势在于某些特定的工作内容,尤其是对于需要经常进行数据存取的任务。 NUMA架构在逻辑上遵循对称多处理(SMP)架构。
NUMA架构的特点是:被共享的内存物理上是分布式的,所有这些内存的集合就是全局地址空间。所以处理器访问这些内存的时间是不一样的,显然访问本地内存的速度要比访问全局共享内存或远程访问外地内存要快些。另外,NUMA中内存可能是分层的:本地内存,群内共享内存,全局共享内存。
NUMA 的基本特征是具有多个Node,每个 Node 由多个 CPU组成,并且具有独立的本地内存、 I/O 槽口等。由于其节点之间可以通过互联模块 ( 如称为 Crossbar Switch) 进行连接和信息交互,因此每个 CPU 可以访问整个系统的内存 。显然,访问本地内存的速度将远远高于访问远地内存 ( 系统内其它节点的内存 ) 的速度,这也是非一致存储访问 NUMA 的由来。由于这个特点,为了更好地发挥系统性能,开发应用程序时需要尽量减少不同 CPU 模块之间的信息交互。 我们用Node之间的距离(Distance,抽象的概念)来定义各个Node之间互访资源的开销。
利用 NUMA 技术,可以较好地解决 SMP 系统的扩展问题,在一个物理服务器内可以支持上百个 CPU 。
-
SMP
Symmetric multiprocessing (SMP) involves a symmetric multiprocessor system hardware and software architecture where two or more identical processors connect to a single, shared main memory, have full access to all I/O devices, and are controlled by a single operating system instance that treats all processors equally, reserving none for special purposes. Most multiprocessor systems today use an SMP architecture. In the case of multi-core processors, the SMP architecture applies to the cores, treating them as separate processors.
SMP systems are tightly coupled multiprocessor systems with a pool of homogeneous processors running independent of each other. Each processor, executing different programs and working on different sets of data, has the capability of sharing common resources (memory, I/O device, interrupt system and so on) that are connected using a system bus or a crossbar.
SMP涉及了一个对称多处理硬件和软件架构,在这个架构中两个及以上完全相同的处理器都连接到一个共享的主存,对所有的I/O设备具有完全的访问权限,并有同一个操作系统控制,每个处理器的地位都是平等的。 大部分的多处理器系统都采用了SMP架构。 以多核处理器为例,对称多处理架构就是这些核,SMP把这些核当作不同的处理器。
SMP系统由一组同样的独立运行的处理器紧密联接起来。 每一个处理器执行不同的程序,运行在不同的数据集上,都能够访问由系统总线连接起来的共享资源(内存,I/O设备,中断系统等)。如果两个处理器同时请求访问一个资源(例如同一段内存地址),由硬件、软件的锁机制去解决资源争用问题。
SMP有一个最大的特点就是共享所有资源。多个CPU之间没有区别,平等地访问内存、外设、一个操作系统。也正是由于这种特征,导致了 SMP 服务器的主要问题,那就是它的扩展能力非常有限。对于 SMP 服务器而言,每一个共享的环节都可能造成 SMP 服务器扩展时的瓶颈,而最受限制的则是内存。由于每个 CPU 必须通过相同的内存总线访问相同的内存资源,因此随着 CPU 数量的增加,内存访问冲突将迅速增加,最终会造成 CPU 资源的浪费,使 CPU 性能的有效性大大降低。实验证明, SMP 服务器 CPU 利用率最好的情况是 2 至 4 个 CPU 。
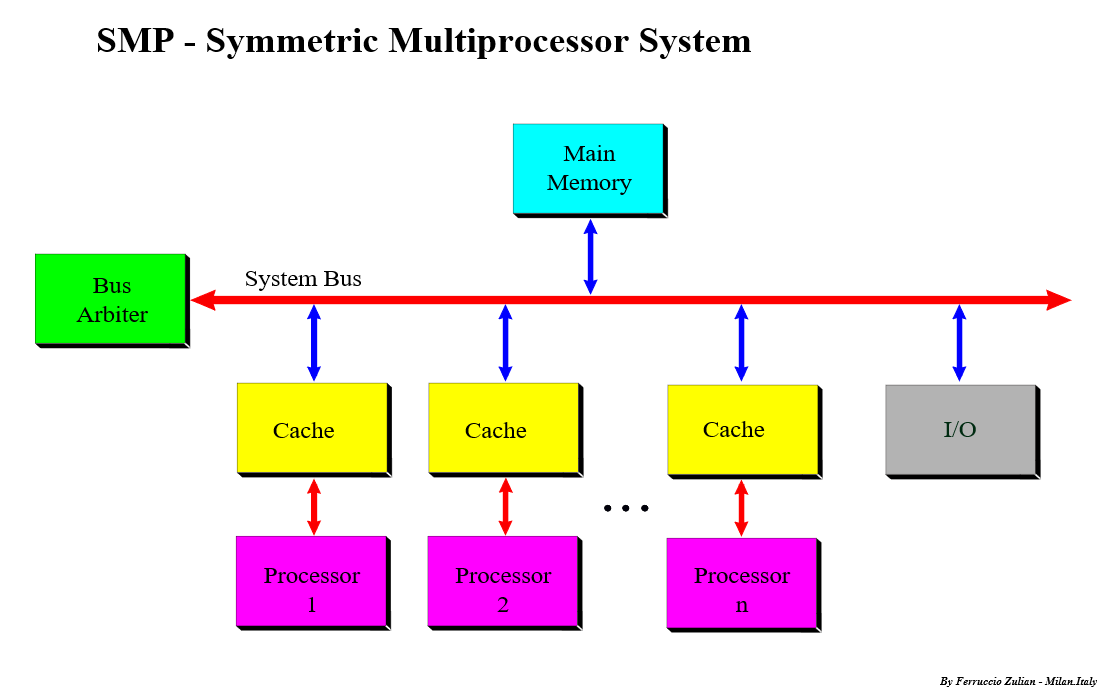
-
HT
Hyper-threading, HT Technology is used to improve parallelization of computations (doing multiple tasks at once) performed on PC microprocessors. For each processor core that is physically present, the operating system addresses two virtual or logical cores, and shares the workload between them when possible. They appear to the OS as two processors, thus the OS can schedule two processes at once.
Node->Socket->Core->Processor
在NUMA架构下,CPU的概念从大到小依次是:Node、Socket、Core、Processor。随着多核技术的发展,将多个CPU封装在一起,这个封装一般被称为Socket(插槽的意思,也有人称之为Packet),而Socket中的每个核心被称为Core。为了进一步提升CPU的处理能力,Intel又引入了HT的技术,一个Core打开HT之后,在OS看来就是两个核,当然这个核是逻辑上的概念,所以也被称为Logical Processor,本文简称为Processor。
一个NUMA Node可以有一个或者多个Socket,一个Socket可以有一个或多个Core,一个Core如果打开HT则变成两个Logical Processor。
Logical processor只是OS内部看到的,实际上两个Processor还是位于同一个Core上,所以频繁的调度仍可能导致资源竞争,影响性能。
如下图中,Node个数为1,Node中有一个Socket,Socket中有2个Core,未开启HT功能。
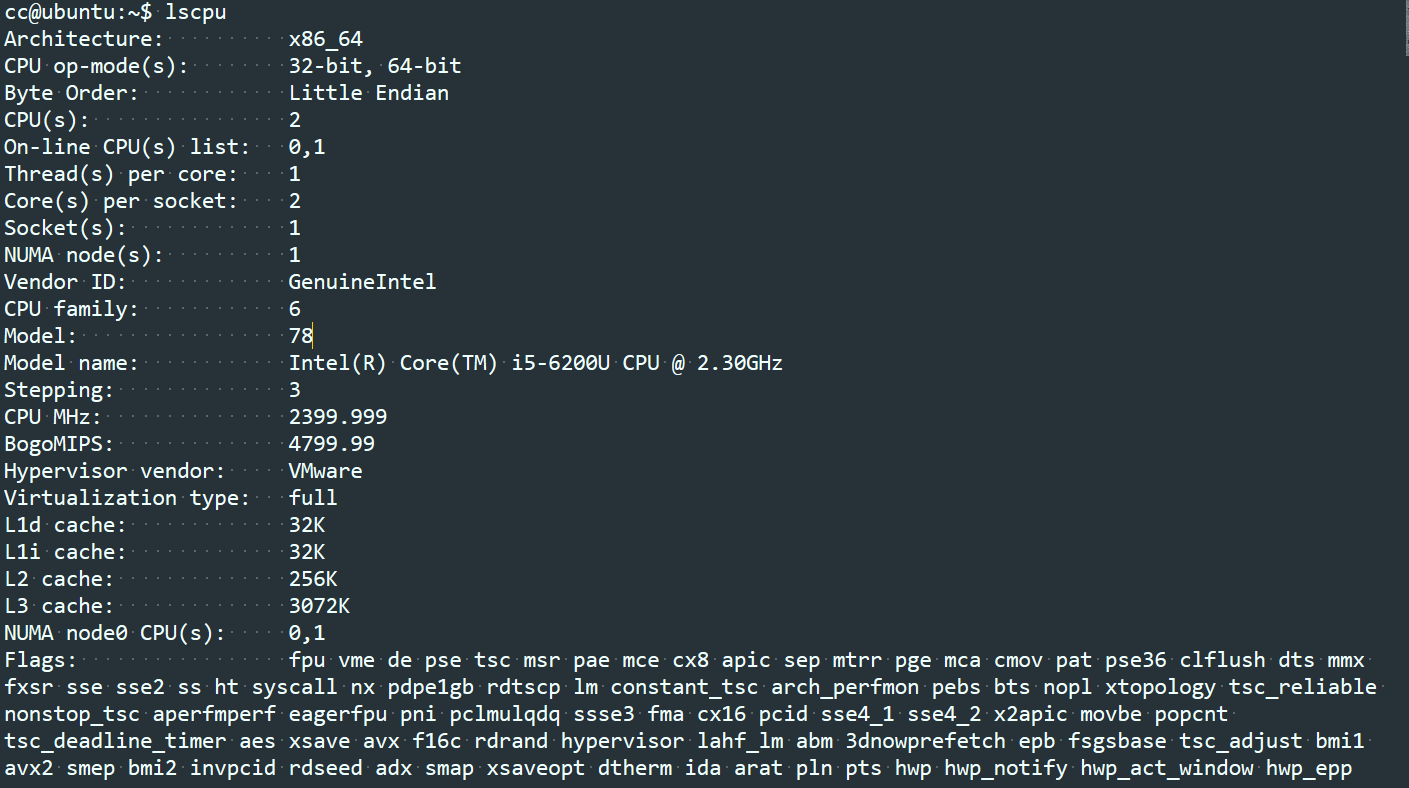
Node信息查询
-
命令numactrl
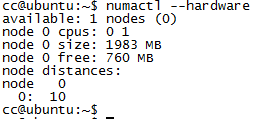
-
通过sys文件系统查看
在目录 /sys/devices/system/node下可以查看系统中的node信息。
Socket信息查询
-
lscpu命令中的Socket(s)
-
proc文件系统cpuinfo中的 physical id
cat /proc/cpuinfo |grep -i "physical id" |sort -u |wc -l
Core信息查询
-
lscpu命令中的Core(s) per socket
-
proc文件系统cpuinfo中的cpu cores和core id
cpu cores表示socket中的core个数 core id表示core在socket中的编号
processor信息查询
-
lscpu命令中的 Thread(s) per core
-
proc文件系统cpuinfo中的 processor
sysfs中cpu信息说明
cpu的拓扑信息可以通过sysfs来查看,在某些架构中,sysfs中的信息与/proc/cpuinfo中的相同。
-
1) /sys/devices/system/cpu/cpuX/topology/physical_package_id
表示cpuX的物理槽位的id。 通常情况下该值与socket id相同,具体的真实值依赖于平台和架构。
-
2) /sys/devices/system/cpu/cpuX/topology/core_id
表示cpuX的core id。 通常情况下指的是硬件平台的id,而不是内核的id。 具体的真实值依赖于平台和架构。
-
3) /sys/devices/system/cpu/cpuX/topology/book_id
表示cpuX的book id。 通常情况下指的是硬件平台的id,而不是内核的id。 具体的真实值依赖于平台和架构。
-
4) /sys/devices/system/cpu/cpuX/topology/thread_siblings
cpuX所在core的逻辑处理器的列表(用于内核内部)
-
5) /sys/devices/system/cpu/cpuX/topology/thread_siblings_list
cpuX所在core的逻辑处理器的列表(用于人可读的)
-
6) /sys/devices/system/cpu/cpuX/topology/core_siblings
cpuX所在socket的逻辑processor的列表(用于内核内部)
-
7) /sys/devices/system/cpu/cpuX/topology/core_siblings_list
cpuX所在socket的逻辑processor的列表(用于人可读的)
-
8) /sys/devices/system/cpu/cpuX/topology/book_siblings
cpuX所在book的逻辑processor的列表(用于内核内部)
-
9) /sys/devices/system/cpu/cpuX/topology/book_siblings_list
cpuX所在book的逻辑processor的列表(用于人可读的)
第4 - 9 项与体系结构无关,是在linux-4.4.23/drivers/base/topology.c中定义的。
三个与book相关的文件(3/8/9)只有编译选项中配置了CONFIG_SCHED_BOOK时才会创建。
如果某个体系结构需要支持上述的1-3的特性,那么必须在arch/xxx/include/asm/topology.h中实现下面的宏定义:
#define topology_physical_package_id(cpu)
#define topology_core_id(cpu)
#define topology_book_id(cpu)
#define topology_sibling_cpumask(cpu)
#define topology_core_cpumask(cpu)
#define topology_book_cpumask(cpu)
*_id 宏定义的类型是int。 *_cpumask 宏定义的类型是 const struct cpumask*。 该宏定义与sysfs系统中的*_sibling的属性相对应(topology_sibling_cpumask()与thread_siblings对应)。
为了能支持所有的体系架构, include/linux/topology.h头文件提供了所有在 include/xxx/include/asm/topology.h 头文件中未定义的上述所有宏的默认的定义:
- physical_package_id: -1
- core_id: 0
- sibling_cpumask: just the given CPU
- core_cpumask: just the given CPU
对于不支持books特性(CONFIG_SCHED_BOOK)的体系架构,topology_book_id() 和 topology_book_cpumask() 没有默认的定义。
另外,/sys/devices/system/cpu文件中也包含了cpu的拓扑信息。 []中的内容是对应的实际值。
- kernel_max: 内核配置的其允许的最大cpu数的index值 [NR_CPUS - 1]
- offline: 由于被热插拔(HOTPLUGGED)或超过了内核配置的最大数量(kernel_max)而导致not online的CPU [~cpu_online_mask + cpus >= NR_CPUS]
- online: 在线且能够被调度的cpu [cpu_online_mask]
- possible: CPUs that have been allocated resources and can be brought online if they are present. [cpu_possible_mask]
- present: CPUs that have been identified as being present in the system. [cpu_present_mask]
上述内容的输出格式适用于cpulist_parse()函数(定义在头文件 linux/cpumask.h中)。 下面是相关的几个例子:
在第一个例子中,系统硬件可以支持64 CPUs,但是32-63号的cpu超过了内核配置的最大值32(0 … 31)。 2号及4-31号cpu是非在线的,但是但同时满足present和possible时这些可以变成online状态。
kernel_max: 31
offline: 2,4-31,32-63
online: 0-1,3
present: 0-31
第二个例子中,NR_CPUS配置项为128,但是内核配置的possible_cpus=144。 系统中有4个cpus,同时2号cpu被认为设置为offline状态(这个是唯一可以变为online的cpu)
kernel_max: 127
offline: 2,4-127,128-143
online: 0-1,3
present: 0-3
可以通过 cpu-hotplug.txt文件查看 possible_cpus=NUM 相关及更多其他内容。
CPU热拔插
在现代的体系架构中处理器引进了高级的错误上报和修正机制。 CPU架构允许对CPU进行分区,这使得单个CPU资源也可以提供一个可用的虚拟环境。 有很多支持NUMA的硬件都支持热拔插功能。 CPU的这种高级功能也需要内核的支持CPU的热拔插。
一个更具新意的CPU热插拔的应用是对SMP系统的挂起/恢复的支持。多核或HT技术使得在一台笔记本上也能运行SMP内核,但是目前的支持挂起/恢复的SMP技术还在研发中。
CPU热拔插相关的命令行开关:
-
maxcpus=n 限制启动时的cpu数为n。 如果系统中有4个cpu,同时使用了maxcpus=2的配置,那么启动时也只能启用2个cpu。可以在系统启动后再将其他cpu热插入。
-
additional_cpus=n 使用该选型限制可以热拔插的cpu数量。 通过该选项可以计算出系统能够支持的最大CPU个数: cpu_possible_mask = cpu_present_mask + additional_cpus 该选项只是用于ia64体系结构的cpu。
-
cede_offline={“off”, “on”} 使用该选项来 禁用/启动 offline 的处理器进入一种扩展状态: H_CEDE。 如果没有特殊说明, cede_offline 被设置为”on”。
-
possible_cpus=n x86_64体系架构使用该选项配置可拔插的cpu。 该选项的值会用于设置cpu_possible_mask。
CPU位图相关信息:
-
cpu_possible_mask: 系统中所有可用的可能的cpu位图。 在系统引导时,使用该项为per_cpu类型的变量申请内存, per_cpu 变量所占的内存在CPU热拔插时不会进行相应的扩展和释放。 一旦在启动是的探测阶段完成了对给位图的设置,它在整个系统运行过程中就是静态的, 也就是说在任何时候都无需设置或清除其中的任何一位。
-
cpu_online_mask: 当前系统中所有处于online的cpu的位图。 这个位图信息是在 __cpu_up()函数中设置的(当cpu能够执行内核调度和接受设备中断时), 当使用__cpu_disable()函数禁用某个CPU时,在所有的系统服务(包括中断在内)都被迁移到其它的CPU之前,需要清除此位图中相应的位。
-
cpu_present_mask: 当前系统中所有在位的cpu的位图。 并不是所有在位的cpu都是online状态的。 当物理的热插拔操作被相关的子系统(如,ACPI)处理之后,需要根据热插拔的情况对改位图进行相应的修改。目前还没有加锁规则。该位图典型的应用是在启动时初始化拓扑结构,而此时热插拔是禁用的。
在大部分情况下cpu位图都是只读的,你无需去修改它。在设置每一个per_cpu类型的变量是,总是使用 cpu_possible_mask/for_each_possible_cpu() 来进行循环处理。
不要使用除了cpumask_t以外的方式来描述一个CPU位图
#include <linux/cpumask.h>
for_each_possible_cpu - Iterate over cpu_possible_mask
for_each_online_cpu - Iterate over cpu_online_mask
for_each_present_cpu - Iterate over cpu_present_mask
for_each_cpu(x,mask) - Iterate over some random collection of cpu mask.
下面的两个函数用于约束[inhibit]CPU的热插拔操作。这两个函数实际上是在操作cpu_hotplug.refcount。当cpu_hotplug.refcount非0时,不能改变cpu_online_mask的值。如果仅仅需要避免CPU被禁用,也可以在临界区前后使用preempt_disable()/preempt_enable()。但是需要注意的是,临界区中不能调用任何能够引起睡眠或将此进程调度走的函数。只要用来关闭处理器的函数stop_machine_run()被调用,preempt_disable()就会执行。
#include <linux/cpu.h>
get_online_cpus() and put_online_cpus():
CPU热拔插的FAQ:
Q: 如何配置内核是能CPU热拔插功能? A: 在对内核进行编译选项配置时,配置内核支持CPU热拔插功能:
"Processor type and Features" -> Support for Hotpluggable CPUs
配置该选项是要确保 CONFIG_SMP 选项也是打开的。 如果需要支持SMP 的挂起/恢复功能,还要打开 CONFIG_HOTPLUG_CPU 编译选项。
Q: 支持CPU热拔插的架构有哪些? A: 在2.6.14及以后的内核中, 下面的体系结构都支持CPU热拔插功能。 i386 (Intel), ppc, ppc64, parisc, s390, ia64 and x86_64
Q: 如何测试新编译的一个内核是否支持热拔插功能? A: 可以观察sysfs文件系统中的一些文件来确认。 首先确认 sysfs 文件系统是否已经挂载。 执行 “mount” 命令。 注意命令的输出中是否有意下面的信息
...
none on /sys type sysfs (rw)
...
如果有上面的信息,就表示sysfs未挂载,执行下面的步骤
mkdir /sysfs
mount -t sysfs sys /sys
现在可以查看所有在位CPU的信息了。 下面的例子中展示的是一个有8个处理器的系统。
#pwd
#/sys/devices/system/cpu
#ls -l
total 0
drwxr-xr-x 10 root root 0 Sep 19 07:44 .
drwxr-xr-x 13 root root 0 Sep 19 07:45 ..
drwxr-xr-x 3 root root 0 Sep 19 07:44 cpu0
drwxr-xr-x 3 root root 0 Sep 19 07:44 cpu1
drwxr-xr-x 3 root root 0 Sep 19 07:44 cpu2
drwxr-xr-x 3 root root 0 Sep 19 07:44 cpu3
drwxr-xr-x 3 root root 0 Sep 19 07:44 cpu4
drwxr-xr-x 3 root root 0 Sep 19 07:44 cpu5
drwxr-xr-x 3 root root 0 Sep 19 07:44 cpu6
drwxr-xr-x 3 root root 0 Sep 19 07:48 cpu7
在每一个目录下,都包含一个 online 的文件,该文件可用于设置对应的处理器逻辑上的 online/offline的状态。
Q: 热拔插操作是否对应CPU物理上的增加和移除? A: 热拔插的使用与其字面上的意义并不完全一致。 配置了CONFIG_HOTPLUG_CPU选项后内核就支持CPU逻辑上的使能/禁止操作。 如果想要支持物理上的添加/删除,需要BIOS的回调以及平台上具有类似PCI设备热拔插的按钮。 配置了CONFIG_ACPI_HOTPLUG_CPU选项后就使得ACPI能够支持CPU在物理上的添加/删除操作。
Q: 怎么设置CPU逻辑上的禁用? A: 执行下面操作即可
echo 0 > /sys/devices/system/cpu/cpuX/online
如果逻辑上禁用成功,可以通过检查 /proc/interrupts 文件来确认。 在该文件中,看不到禁用CPU的相关信息。 通过查看 /sys/devices/system/cpu/cpuX/online 文件确认对应cpu的当前状态,0表示offline,1表示online。
Q: 某些系统中,为什么不能移除CPU0? A: 一些体系架构中对于某些CPU会有特殊的依赖关系。 比如,在IA64中,我们可以发送平台中断给操作系统,也就是可修正的平台错误中断(CPEI)。 如果ACPI不支持这中断重定向到其他CPU功能(即中断只能发给特定的CPU),那么该CPU是不能被移除的。 在这种情况下,sysfs文件系统中对应的cpu0目录下就没有online文件。
Q: X86中的CPU0是否是可移除的? A: 是的。如果内核配置了编译选项 CONFIG_BOOTPARAM_HOTPLUG_CPU0=y,那么CPU0就是可以移除的。 另外还可以通过内核选项cpu0_hotplug来配置CPU0可移除。 但是某些特性需要依赖CPU0,如下:
- Resume from hibernate/suspend depends on CPU0. Hibernate/suspend will fail if CPU0 is offline and you need to online CPU0 before hibernate/suspend can continue.
- PIC interrupts also depend on CPU0. CPU0 can’t be removed if a PIC interrupt is detected. It’s said poweroff/reboot may depend on CPU0 on some machines although I haven’t seen any poweroff/reboot failure so far after CPU0 is offline on a few tested machines.
Q: 怎样确认某个CPU是不可移除的? A: 这个依赖于具体的实现, 某些架构对于这种CPU可能不存在online文件。 这种情况适用于能够提前判断该CPU不能移除的情况。 另外,还可以通过运行时检查实现,如当尝试移除最后一个CPU时,可以通过echo信息提示操作失败。
Q: 但对一个CPU进行逻辑上的移除时,具体会做哪些操作? A: 会发生下面的事情,排列是无序的。
- 内核模块会接收到 CPU_DOWN_PREPARE或 CPU_DOWN_PREPARE_FROZEN事件。 具体是哪个事件依赖于CPU被移除时,是否存在处于frozen的任务。
- 该CPU上的所有处理都被迁移到其他CPU上,具体迁移到哪个CPU是由每个任务当前的cpusset决定的, 它可能是所有处于online状态的CPU的子集。
- 所有需要上报到该CPU的中断都被迁移到其他CPU
- 定时器/中断下半部/tasklets也都会被迁移到其他CPU
- 一旦所有的服务都被迁移,内核就会调用一个体系相关的例程(__cpu_disable())来完成清理动作
- 当清理完成后,会上报事件 CPU_DEAD / CPU_DEAD_FROZEN
当CPU_DOWN_PREPARE事件处理函数被调用后,所有的服务都要被清理。 当CPU_DEAD处理函数调用时,不应该有任何东西还运行在该CPU。
Q: 怎么做才能使内核代码需要感知到CPU的接入和移除? A: 下面的代码表示接受到相应的通知时的处理。
#include <linux/cpu.h>
static int foobar_cpu_callback(struct notifier_block *nfb, unsigned long action, void* hcpu)
{
unsigned int cpu = (unsigned long)hcpu;
switch(action)
{
case CPU_ONLINE:
case CPU_ONLINE_FROZEN:
foobar_online_action(cpu);
break;
case CPU_DEAD_FROZEN:
foobar_dead_action(cpu);
break;
};
return NOTIFY_OK;
}
static struct notifier_block foobar_cpu_notifier =
{
.notifier_call = foobar_cpu_callback,
}
需要在初始化函数中调用 register_cpu_notifier() 。 该初始化函数应该属于下面类型中的一个:
- early init(只有当启动处理器时才会调用的init函数)
- late init(当所有的CPU都online后才会调用的init函数)
当采用第一种情况时,需要在init函数中添加下面的代码
register_cpu_notifier(&foobar_cpu_notifier);
当采用第二种情况时,需要在init函数中添加下面的代码
register_hotcpu_notifier(&foobar_cpu_notifier);
如果在准备资源的时候出现问题会导致注册notifier失败。 这是会终止活动,然后发送一个CANCELED事件。
CPU_DEAD不应该失败,它仅仅是在通知一个好消息。当接收到一个BAD通知时,则意味着可能会发生坏事情。
Q: action调用次数与所有已经运行的CPU的数量不一致。 A: 是的,CPU notifiers只有当此新的CPU被使能(on-lined)或禁用(offlined)时才会调用。 如果你需要对系统的每一个CPU都执行相应的action,参考下面的代码。
for_each_online_cpu(i)
{
foobar_cpu_callback(&foobar_cpu_notifier, CPU_UP_PREPARE, i);
foobar_cpu_callback(&foobar_cpu_notifier, CPU_ONLINE, i);
}
如果你需要注册一个hotplug的回调处理,期望对已经处于online的CPU执行一些初始化错误,可以参考下面的方式:
Version 1: (Correct)
cpu_notifier_register_begin();
for_each_online_cpu(i)
{
foobar_cpu_callback(&foobar_cpu_notifier, CPU_UP_PREPARE, i);
foobar_cpu_callback(&foobar_cpu_notifier, CPU_ONLINE, i);
}
/* Note the use of the double underscored version of the API */
__register_cpu_notifier(&foobar_cpu_notifier);
cpu_notifier_register_done();
注意下面的版本是不正确的方式,因为它有可能导致cpu_add_remove_lock 和 cpu_hotplug.lock之间的ABBA死锁。
Version 2: (Wrong!!!)
get_online_cpus();
for_each_online_cpu(i)
{
foobar_cpu_callback(&foobar_cpu_notifier, CPU_UP_PREPARE, i);
foobar_cpu_callback(&foobar_cpu_notifier, CPU_ONLINE, i);
}
register_cpu_notifier(&foobar_cpu_notifier);
put_online_cpus();
如果希望为已经处于online的CPU注册回调函数进行初始化时,一定要选用上面的Version 1。
Q: 如果想对一种新的体系结构开发CPU热拔插的支持,最少需要哪些工作? A: 想要CPU热拔插基础框架能够正常工作,需要以下步骤:
* 确保Kconfig中添加了 CONFIG_HOTPLUG_CPU 的使能功能。
* __cpu_up() 体系结构中使能cpu的接口
* __cpu_disable() 体系结构中关闭cpu的接口, 当该函数返回后,内核不会再处理中断。 局部APIC定时器也会被关闭。
* __cpu_die() 这个接口实际上用于确认CPU真的已经关闭。最好参考下其他已经实现CPU热拔插的体系结构的代码。
__cpu_die()通常会等待某些 per_cpu的状态被设置,以确保处理器的关闭处理被正确的调用。
Q: 如何确保某个正在执行某些特殊任务的CPU不能被移除? A: 有两种方式。 如果你的代码可以运行在中断上下文,可以使用 smp_call_function_single() ,否则使用 work_on_cpu() 。 注意 work_on_cpu() 函数执行很慢,有可能会导致out of memory。
int my_func_on_cpu(int cpu)
{
int err;
get_online_cpus();
if (!cpu_online(cpu))
err = -EINVAL;
else
#if NEEDS_BLOCKING
err = work_on_cpu(cpu, __my_func_on_cpu, NULL);
#else
smp_call_function_single(cpu, __my_func_on_cpu, &err, true);
#endif
put_online_cpus();
return err;
}
Q: 如何确定有多少个CPU可以热拔插? A: 到目前,ACPI都没有给出明确的信息。 Unisys的Natalie指出,ACPI的MADT(Multiple APIC Description Tables)可以将系统中可用的CPU标记为禁用状态。 Andi实现了一些简单的启发式方法,可以统计出MADT表中被禁用的CPU的个数,这些CPU就是可以用于热插拔的CPU。在没有被禁用的CPU的情况下,我们假设当前可用CPU的一半可以用于热插拔。
忠告:在ACPI2.0c以及以前的版本中, ACPI MADT仅能提供256个表项,因为MADT中的apicid字段仅有8位。 从ACPI3.0 开始,这个限制已经取消了, apicid字段已经扩展到了32bits。
用户空间的通知机制
在linux中,对设备的热拔插已经普遍支持了。 可以使用热拔插机制来自动配置网络,usb和pci设备。 一个热拔插事件可以唤醒一个代理脚本,用于执行某些配置任务。
在用户空间中可以添加 /etc/hotplug/cpu.agent 用于处理热拔插事件。
#!/bin/bash
# $id: cpu.agent
# Kernel hotplug params include:
# ACTION=%s [online or offline]
# DEVPATH=%s
#
cd /etc/hotplug
../hotplug.functions
case $ACTION in
online)
echo `date` ":cpu.agent" add cpu >> /tmp/hotplug.txt
;;
offline)
echo `date` ":cpu.agent" remove cpu >> /tmp/hotplug.txt
;;
*)
debug_mesg CPU $ACTION event not supported
exit 1
;;
esac