Welcome to My Blog!
-
C++ primer 读书笔记(一)--- 变量和数据类型
默认环境: Ubuntu 16.04 + gcc 5.3.1 + intel x86_64
变量和基本类型
-
字符型被分成了三种:
char/signed char/unsigned char。尽管字符型有三种,但是字符的表现形式却只有两种: 带符号和无符号的。类型char具体表现为上述两种形式的哪一个,是由编译器决定的。 因为类型char在一些机器上是有符号的,在另外一些机器上又是无符号的,所以如果使用char进行算数运算特别容易出问题,如果需要使用一个不大的整数时,那么明确指定它的类型是signed char或unsigned char。 -
执行浮点运算时通常使用
double,这是因为float通常精度不够而且双精度浮点数和单精度浮点数的计算代价相差无几。事实上,对于某些机器来说,双精度运算甚至比单精度运算还快。 -
C++ 算术类型
类型 含义 最小尺寸 bool 布尔类型 未定义 char 字符 8位 wchar_t 宽字符 16位 char16_t Unicode字符 16位 char32_t Unicode字符 32位 short 短整型 16位 int 整型 16位 long 长整型 32位 long long 长整型 64位 float 单精度浮点数 6位有效位 double 双精度浮点数 10位有效位 long double 扩展精度浮点数 10位有效位 C++语言规定,
int类型的大小要 >=short,long类型大小 >=int,long long类型大小 >=long。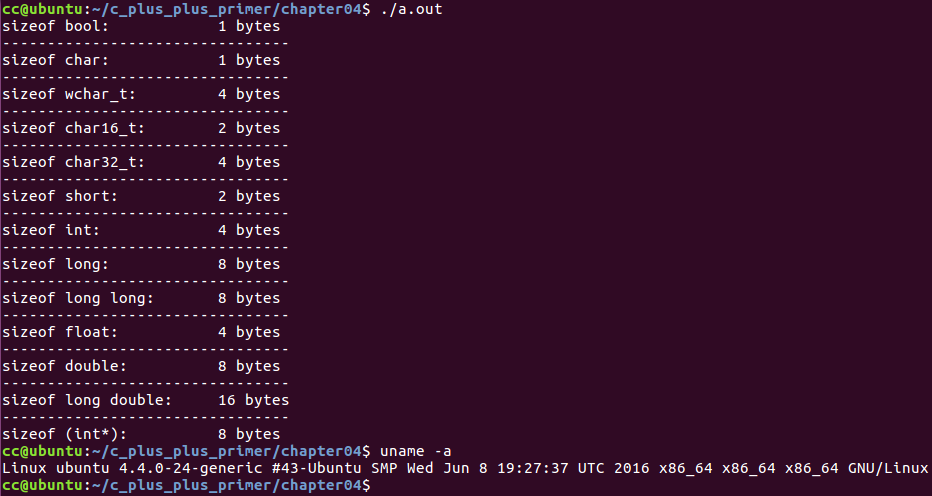
强制类型转换
一些基本规则
-
把一个浮点数赋给整数类型时,仅保留浮点数中小数点之前的部分。
-
把一个整数赋给浮点数类型时,小数部分记为0。如果该整数所占的空间超过了浮点类型的容量,精度可能有损失。
-
赋给无符号整数类型一个超出它表示范围的值时,结果是初始值对无符号类型表示数值总个数取模后的余数(从二进制上看,相当于将前面超出表示范围的位都丢掉)。
-
赋给有符号整数类型一个超出它表示范围的值时,结果时未定义的(undefined)。程序可能继续工作,可能崩溃,也可能生成垃圾数据。
int i = 3.14; //i的值为3 double pi = 3; //pi的值为3.0 unsigned char c = -1; //假设char占8bits,c的值为255 //编译时会告警,c的值为66,因为unsigned char能表示的数值为0~255,有256个,322 % 256 = 66 //322 用二进制表示为0000 0001 0100 0010 = 0x0142 //inter 采用小端模式存储数据,0x42保存在低地址 //unsigned char能表示的有效位只有8bits,所以只有低8位是有效数据,c的值为0x42,即66 c = 322; signed char c2 = 322; //假设char占8bits, c2的值是未定义的,gcc 输出结果为66 -
当一个算术表达式中既有无符号数又有int值时,那个int值会转换为无符号数,编程时要尽量避免这种情况发生。因为带符号数为负数时,可能会出现不是我们所期望的结果,把负数转换成无符号数时,会将该负数按照无符号数的规则去解析,出现符号位的反转。
隐式强制类型转换发生条件
- 在大多数表达式中,比
int类型小的整型值首先提升为较大的整数类型 - 在条件表达式中,非布尔值转换成布尔类型
- 初始化过程中,初始值转换成变量的类型;在赋值语句中,右侧运算对象转换成左侧运算对象的类型
- 如果算术运算或关系运算的运算对象有多种类型,需要转换成同一种类型
- 函数调用时也会发生类型转换
算术类型之间的隐式转换被设计得尽可能避免损失精度。很多时候,如果表达式中既有整数类型的运算对象也有浮点数类型的运算对象,整型会转换成浮点数。 例如,下面的表达式:
int ival = 3.541 + 3;
表达式中的3首先转换成double类型,然后执行浮点数加法,所得结果的类型是double。接下来就是完成初始化的任务了,在初始化时,因为被初始化的对象的类型无法改变,所以初始值被转换成该对象的类型,即double类型的结果被转换成int类型的值。隐式转换之算术转换
-
算术转换的含义是把一种算术类型转换成另外一种算术类型。 算术转换的规则定义了一套类型转换的层次,其中运算符的运算对象将转换成最宽的类型。例如,如果一个运算对象的类型是
long double,那么不论另外一个运算对象的类型是什么都会转换成long double。 还有一种更普遍的情况,当表达式中既有浮点类型也有整数类型时,整数值将转换成相应的浮点类型。 -
整型提升
整型提升负责把小整数类型转换成较大的整数类型。对于
bool、char、signed char、unsigned char、short和unsigned short等类型来说,只要他们所有的可能值都能存在int里,它们就会提升成int类型;否则提升成unsigned int类型。 较大的char类型(wchar_t、char16_t、char32_t)提升成int、unsigned int、long、unsigned long、long long和unsigned long long中最小的一种类型,前提是转换后的类型要能容纳原类型所有可能的值。 -
无符号类型的运算对象
如果某个运算符的运算对象类型不一致,这些运算对象将转换成同一种类型。但是如果某个运算对象的类型是无符号类型,那么转换的结果就要依赖于机器中各个整数类型的相对大小了。
-
首先进行整型提升。
- 如果结果的类型匹配,无须进行进一步的转换。两个(提升后的)运算对象的类型要么都是带符号的、要么都是无符号的,则小类型的运算对象转换成较大类型。
- 如果一个运算对象是无符号类型,另外一个运算对象是带符号类型。
- 无符号类型不小于带符号类型,那么带符号的运算对象转换成无符号的。例如,假设两个类型分别是
unsigned int和int,则int类型的运算对象转换成unsigned int类型。需要注意的是,如果int类型的值恰好为负值,可能会出现不是我们所期望的结果(符号位反转)。 - 带符号类型大于无符号类型,此时转换的结果依赖于机器。
- 如果无符号类型的所有值都能存在该带符号类型中,则无符号类型的运算对象转换成带符号类型。
-
如果不能,那么带符号类型的运算对象转换成无符号类型。
例如,如果两个运算对象的类型分别是
long和unsigned int,并且int和long的大小相同,则long类型的运算对象转换成unsigned int类型; 如果long类型占用的空间比int更多,则unsigned int类型的运算对象转换成long类型。
- 无符号类型不小于带符号类型,那么带符号的运算对象转换成无符号的。例如,假设两个类型分别是
-
-
算术转换举例
bool flag; char cval; short sval; unsigned short usval; int ival; unsigned int uival; long lval; unsigned long ulval; float fval; double dval; 3.141592L + 'a'; // 'a'提升成int,然后int转换成long double dval + ival; // ival 转换成 double dval + fval; // fval 转换成 double ival = dval; // dval 转换成(切除小数部分)int flag = dval; // 如果dval是0,则flag是false,否则flag是true cval + fval; // cval提升成int,然后该int值转换成float sval + cval; // sval 和 cval都提升成int cval + lval; // cval 转换成long ival + ulval; // ival 转换成 unsigned long usval + ival; // 根据unsigned short 和int所占空间的大小进行提升 uival + lval; // 根据unsigned int 和long所占空间的大小进行转换
其他隐式类型转换
-
数组转换成指针
-
在大多数用到数组的表达式中,数组自动转换成指向数组首元素的指针:
int ia[10]; int* ip = ia; // ia转换成指向数组首元素的指针- 当数组被用作
decltype关键字的参数,或者作为取地址符(&)、sizeof及typeid等运算符的运算对象时,上述转换不会发生 -
如果用数组初始化一个引用时,上述转换也不会发生
int arr[10]; int (&arrRef)[10] = arr; // arrRef引用一个含有10个整数的数组
- 当数组被用作
-
-
指针的转换
- 常量整数值0或者字面值
nullptr能转换成任意指针类型 - 指向任意非常量的指针能转换成void*
- 指向任意对象的指针能转换成const void*
- 在有继承关系的类型间还有另外一种指针转换方式
- 常量整数值0或者字面值
-
转换成布尔类型 存在一种从算术类型或指针类型向布尔类型自动转换的机制。如果指针类型或算术类型的值为0,转换结果为false;否则转换结果为true。
-
转换成常量
- 允许将指向非常量类型的指针转换成指向相应的常量类型的指针
- 对于引用也支持上一条的转换
-
相反的转换不不存在
int i; const int &j = i; // 非常量转换成const int的引用 const int *p = &i; // 非常量的地址转换成const的地址 int &r = j, *q = p; // 错误:不允许const转换成非常量
-
类类型定义的转换 类类型能定义由编译器自动执行的转换,不过编译器每次只能执行一种类类型的转换。 如果同时提出多个转换请求,这些请求将被拒绝。
显示转换
-
命名的强制类型转换
cast-name
(expression); type是转换的目标类型
expression是要转换的值
cast-name 是
static_cast、dynamic_cast、const_cast和reinterpret_cast中的一种。- dynamic_cast 支持运行时类型识别
-
static_cast
任何具有明确定义的类型转换,只要不包含底层
const,都可以使用static_cast。int i,j; double slope = static_cast<double>i/j; // 进行强制类型转换以便执行浮点数除法当需要把一个较大的算术类型赋值给较小的类型时,static_cast非常有用。此时,强制类型转换告诉程序的读者和编译器:我们知道并且不在乎潜在的精度损失。一般来说,如果编译器发现一个较大的算术类型试图赋值给较小的类型,就会给出告警信息;但是当我们执行了显式的类型转换后,告警信息就会被关闭了。
static_cast对于编译器无法自动执行的类型转换也非常有用。
double d; void* p = &d; double* dp = static_cast<double*>(p); -
const_cast
const_cast只能改变运算对象的底层const。 只有const_cast能改变表达式的常量属性,使用其他形式的命名强制类型转换改变表达式的常量属性都将引发编译器错误。同样的,也不能使用const_cast改变表达式的类型。
对于将常量对象转换成非常量对象的行为,我们一般称其为“去掉const性质”。一旦我们去掉了某个对象的const性质,编译器就不再阻止我们对该对象进行写操作了。如果对象本身不是一个常量,使用强制类型转换获得写权限是合法的行为。然而如果对象是一个常量,再使用const_cast执行写操作就会产生未定义的后果。
const_cast通常用于函数重载的上下文中。
-
reinterpret_cast
reinterpret_cast通常为运算对象的位模式提供较低层次上的重新解释。 使用reinterpret_cast是非常危险的,它本质上依赖于机器。要想安全的使用reinterpret_cast必须对涉及的类型和编译器实现转换的过程都非常了解。
-
旧式的强制类型转换
type (expr); // 函数形式的强制类型转换 (type)expr; // C语言风格的强制类型转换
与命名的强制类型转换相比,旧式的强制转换类型从表现形式上来说不那么清晰明了,容易被看漏,所以一旦转换过程出现问题,追踪起来更加困难。
强制类型转换干扰了正常的类型检查,因此强烈建议避免使用强制类型转换。这个建议对reinterpret_cast尤其适用,因为此类类型转换总是充满了风险。 在有重载函数的上下文中使用const_cast无可厚非,但是其他情况下使用const_cast也就意味着程序存在某种设计缺陷。 其他强制类型转换,比如static_cast和dynamic_cast,都不应该频繁使用。
字面值常量
-
一个形如
52、'a'、"Hello"、3.14L、99LL、u8"hi!"的值被称为字面值常量(literal)。每个字面值常量都对应一种数据类型,字面值常量的形式(前缀/后缀)和值大小决定了它的数据类型。 -
字符和字符串字面值
由单引号括起来的一个字符称为
char型字面值双括号括起来的零个或多个字符则构成字符串字面值
前缀 含义 类型 u Unicode 16 字符 char16_tU Unicode 32 字符 char32_tL 宽字符 wchar_tu8 UTF-8(仅用于字符串字面常量) char -
整型字面值
默认情况下,十进制不带后缀的整数字面值是带符号数,它的类型是
int/long/long long中能容纳它大小的最小的那个。 八进制和十六进制不带后缀的整数字面值可能是带符号数,也可能是无符号数,它的类型是int/unsigned int/long/unsigned long/long long/unsigned long long中尺寸最小者。 类型short没有对应的字面值。后缀 最小匹配类型 u or U unsignedl or L longll or LL long long -
浮点型字面值
默认的,浮点型字面值是一个
double。后缀 类型 f or F floatl or L long double -
布尔字面值
true和false是布尔类型的字面值 -
指针字面值
nullptr是指针字面值
泛化的转义序列
-
形式为
\x后紧跟1个或多个十六进制数字,或者\后紧跟1个、2个或3个八进制数字,其中数字部分表示的是字符对应的数值。\12(换行符)\115(字符M)\x4d(字符M)std::cout << "Hi, \x4d-O-\155!\n"; //输出: Hi, M-O-M! 然后换行如果反斜线
\后面跟着的八进制数超过3个,只有前3个跟\构成转义序列。 相反,\x要用到后面跟着的所有数字,例如,\x1234表示一个16位的字符,该字符由这4个十六进制数所对应的比特唯一确定。因为大多数机器的char型数据都是占8位,所以上面这个例子可能会报错。一般来说,超过8位的十六进制字符都是与前面的字符与字符串字面值表中的某个前缀作为开头的扩展字符集一起使用的。
-
-
Hello World!
2016-06-24Hello World!