Welcome to My Blog!
-
Linux Kernel cpu拓扑简介
- 参考资料
- 相关概念
- Node->Socket->Core->Processor
- Node信息查询
- Socket信息查询
- Core信息查询
- processor信息查询
- sysfs中cpu信息说明
- CPU热拔插
参考资料
- linux-4.4.23/Documentation/cputopology.txt
- linux-4.4.23/Documentation/cpu-hotplug.txt
- 玩转CPU Topology
- 团子的小窝
- 秦白衣的技术专栏
相关概念
-
NUMA
Non-Uniform memory access is a computer memory design used in multiprocessing, where the memory access time depends on the memory location relative to the processor. Under NUMA, a processor can access its own local memory faster than non-local memory (memory local to another processor or memory shared between processors). The benefits of NUMA are limited to particular workloads, notably on servers where the data are often associated strongly with certain tasks or users. NUMA architectures logically follow in scaling from symmetric multiprocessing (SMP) architectures.
NUMA 是一种为多处理器设计的非一致性内存访问方式,内存存取时间依赖于内存相对于处理器的位置。 在NUMA中,处理器访问它自己本地的内存速度比访问非本地内存(另一个处理器对应的本地内存或多个处理器共享的内存)要快的多。 NUMA的优势在于某些特定的工作内容,尤其是对于需要经常进行数据存取的任务。 NUMA架构在逻辑上遵循对称多处理(SMP)架构。
NUMA架构的特点是:被共享的内存物理上是分布式的,所有这些内存的集合就是全局地址空间。所以处理器访问这些内存的时间是不一样的,显然访问本地内存的速度要比访问全局共享内存或远程访问外地内存要快些。另外,NUMA中内存可能是分层的:本地内存,群内共享内存,全局共享内存。
NUMA 的基本特征是具有多个Node,每个 Node 由多个 CPU组成,并且具有独立的本地内存、 I/O 槽口等。由于其节点之间可以通过互联模块 ( 如称为 Crossbar Switch) 进行连接和信息交互,因此每个 CPU 可以访问整个系统的内存 。显然,访问本地内存的速度将远远高于访问远地内存 ( 系统内其它节点的内存 ) 的速度,这也是非一致存储访问 NUMA 的由来。由于这个特点,为了更好地发挥系统性能,开发应用程序时需要尽量减少不同 CPU 模块之间的信息交互。 我们用Node之间的距离(Distance,抽象的概念)来定义各个Node之间互访资源的开销。
利用 NUMA 技术,可以较好地解决 SMP 系统的扩展问题,在一个物理服务器内可以支持上百个 CPU 。
-
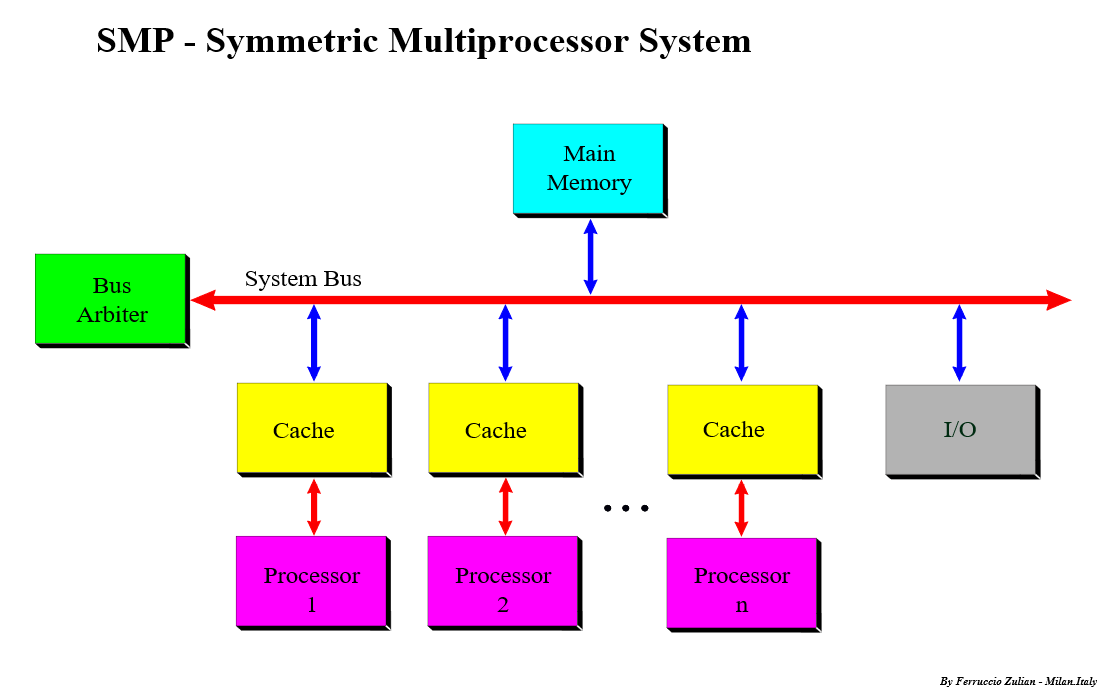
SMP
Symmetric multiprocessing (SMP) involves a symmetric multiprocessor system hardware and software architecture where two or more identical processors connect to a single, shared main memory, have full access to all I/O devices, and are controlled by a single operating system instance that treats all processors equally, reserving none for special purposes. Most multiprocessor systems today use an SMP architecture. In the case of multi-core processors, the SMP architecture applies to the cores, treating them as separate processors.
SMP systems are tightly coupled multiprocessor systems with a pool of homogeneous processors running independent of each other. Each processor, executing different programs and working on different sets of data, has the capability of sharing common resources (memory, I/O device, interrupt system and so on) that are connected using a system bus or a crossbar.
SMP涉及了一个对称多处理硬件和软件架构,在这个架构中两个及以上完全相同的处理器都连接到一个共享的主存,对所有的I/O设备具有完全的访问权限,并有同一个操作系统控制,每个处理器的地位都是平等的。 大部分的多处理器系统都采用了SMP架构。 以多核处理器为例,对称多处理架构就是这些核,SMP把这些核当作不同的处理器。
SMP系统由一组同样的独立运行的处理器紧密联接起来。 每一个处理器执行不同的程序,运行在不同的数据集上,都能够访问由系统总线连接起来的共享资源(内存,I/O设备,中断系统等)。如果两个处理器同时请求访问一个资源(例如同一段内存地址),由硬件、软件的锁机制去解决资源争用问题。
SMP有一个最大的特点就是共享所有资源。多个CPU之间没有区别,平等地访问内存、外设、一个操作系统。也正是由于这种特征,导致了 SMP 服务器的主要问题,那就是它的扩展能力非常有限。对于 SMP 服务器而言,每一个共享的环节都可能造成 SMP 服务器扩展时的瓶颈,而最受限制的则是内存。由于每个 CPU 必须通过相同的内存总线访问相同的内存资源,因此随着 CPU 数量的增加,内存访问冲突将迅速增加,最终会造成 CPU 资源的浪费,使 CPU 性能的有效性大大降低。实验证明, SMP 服务器 CPU 利用率最好的情况是 2 至 4 个 CPU 。
-
HT
Hyper-threading, HT Technology is used to improve parallelization of computations (doing multiple tasks at once) performed on PC microprocessors. For each processor core that is physically present, the operating system addresses two virtual or logical cores, and shares the workload between them when possible. They appear to the OS as two processors, thus the OS can schedule two processes at once.
Node->Socket->Core->Processor
在NUMA架构下,CPU的概念从大到小依次是:Node、Socket、Core、Processor。随着多核技术的发展,将多个CPU封装在一起,这个封装一般被称为Socket(插槽的意思,也有人称之为Packet),而Socket中的每个核心被称为Core。为了进一步提升CPU的处理能力,Intel又引入了HT的技术,一个Core打开HT之后,在OS看来就是两个核,当然这个核是逻辑上的概念,所以也被称为Logical Processor,本文简称为Processor。
一个NUMA Node可以有一个或者多个Socket,一个Socket可以有一个或多个Core,一个Core如果打开HT则变成两个Logical Processor。
Logical processor只是OS内部看到的,实际上两个Processor还是位于同一个Core上,所以频繁的调度仍可能导致资源竞争,影响性能。
如下图中,Node个数为1,Node中有一个Socket,Socket中有2个Core,未开启HT功能。
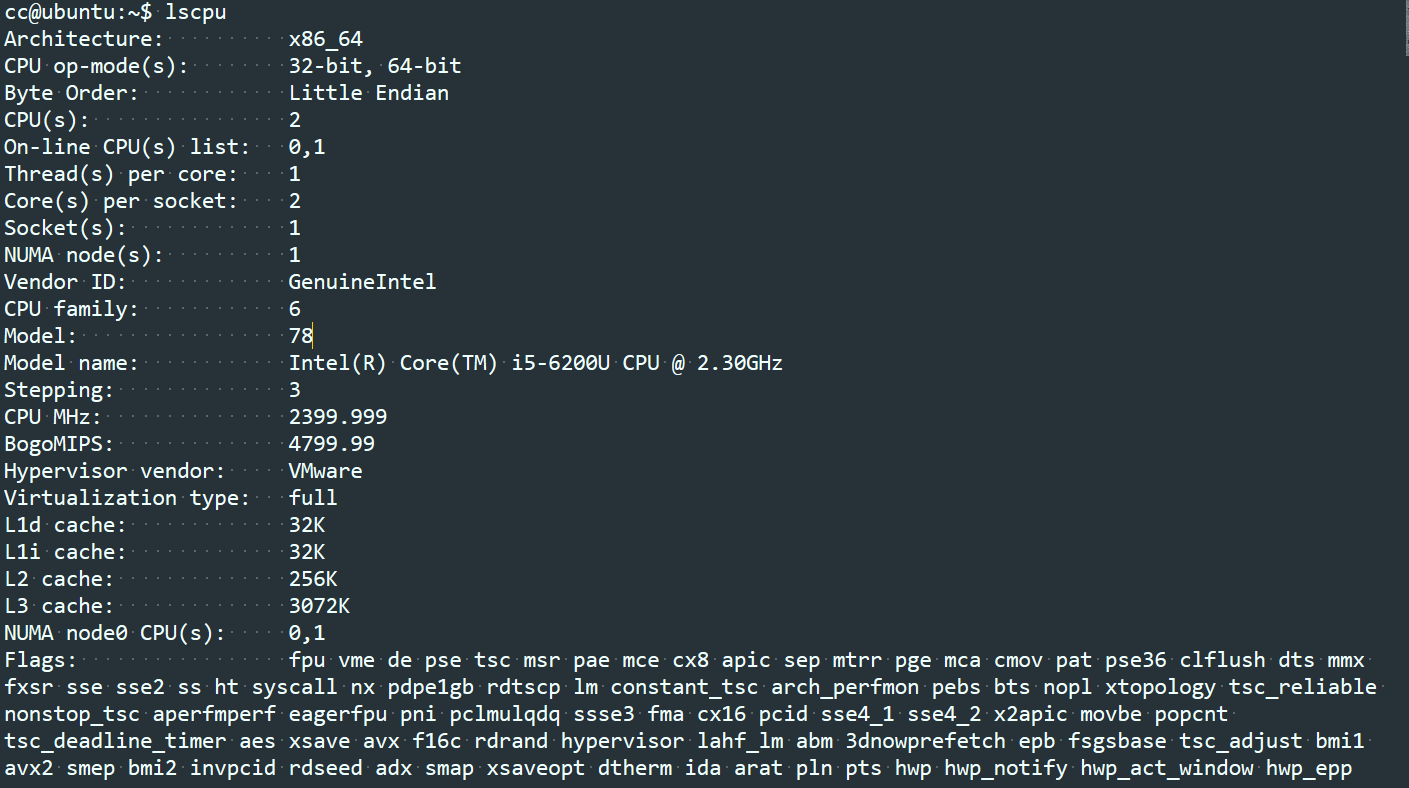
Node信息查询
-
命令numactrl
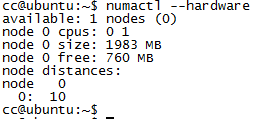
-
通过sys文件系统查看
在目录 /sys/devices/system/node下可以查看系统中的node信息。
Socket信息查询
-
lscpu命令中的Socket(s)
-
proc文件系统cpuinfo中的 physical id
cat /proc/cpuinfo |grep -i "physical id" |sort -u |wc -l
Core信息查询
-
lscpu命令中的Core(s) per socket
-
proc文件系统cpuinfo中的cpu cores和core id
cpu cores表示socket中的core个数 core id表示core在socket中的编号
processor信息查询
-
lscpu命令中的 Thread(s) per core
-
proc文件系统cpuinfo中的 processor
sysfs中cpu信息说明
cpu的拓扑信息可以通过sysfs来查看,在某些架构中,sysfs中的信息与/proc/cpuinfo中的相同。
-
1) /sys/devices/system/cpu/cpuX/topology/physical_package_id
表示cpuX的物理槽位的id。 通常情况下该值与socket id相同,具体的真实值依赖于平台和架构。
-
2) /sys/devices/system/cpu/cpuX/topology/core_id
表示cpuX的core id。 通常情况下指的是硬件平台的id,而不是内核的id。 具体的真实值依赖于平台和架构。
-
3) /sys/devices/system/cpu/cpuX/topology/book_id
表示cpuX的book id。 通常情况下指的是硬件平台的id,而不是内核的id。 具体的真实值依赖于平台和架构。
-
4) /sys/devices/system/cpu/cpuX/topology/thread_siblings
cpuX所在core的逻辑处理器的列表(用于内核内部)
-
5) /sys/devices/system/cpu/cpuX/topology/thread_siblings_list
cpuX所在core的逻辑处理器的列表(用于人可读的)
-
6) /sys/devices/system/cpu/cpuX/topology/core_siblings
cpuX所在socket的逻辑processor的列表(用于内核内部)
-
7) /sys/devices/system/cpu/cpuX/topology/core_siblings_list
cpuX所在socket的逻辑processor的列表(用于人可读的)
-
8) /sys/devices/system/cpu/cpuX/topology/book_siblings
cpuX所在book的逻辑processor的列表(用于内核内部)
-
9) /sys/devices/system/cpu/cpuX/topology/book_siblings_list
cpuX所在book的逻辑processor的列表(用于人可读的)
第4 - 9 项与体系结构无关,是在linux-4.4.23/drivers/base/topology.c中定义的。
三个与book相关的文件(3/8/9)只有编译选项中配置了CONFIG_SCHED_BOOK时才会创建。
如果某个体系结构需要支持上述的1-3的特性,那么必须在arch/xxx/include/asm/topology.h中实现下面的宏定义:
#define topology_physical_package_id(cpu) #define topology_core_id(cpu) #define topology_book_id(cpu) #define topology_sibling_cpumask(cpu) #define topology_core_cpumask(cpu) #define topology_book_cpumask(cpu)*_id 宏定义的类型是int。 *_cpumask 宏定义的类型是 const struct cpumask*。 该宏定义与sysfs系统中的*_sibling的属性相对应(topology_sibling_cpumask()与thread_siblings对应)。
为了能支持所有的体系架构, include/linux/topology.h头文件提供了所有在 include/xxx/include/asm/topology.h 头文件中未定义的上述所有宏的默认的定义:
- physical_package_id: -1
- core_id: 0
- sibling_cpumask: just the given CPU
- core_cpumask: just the given CPU
对于不支持books特性(CONFIG_SCHED_BOOK)的体系架构,topology_book_id() 和 topology_book_cpumask() 没有默认的定义。
另外,/sys/devices/system/cpu文件中也包含了cpu的拓扑信息。 []中的内容是对应的实际值。
- kernel_max: 内核配置的其允许的最大cpu数的index值 [NR_CPUS - 1]
- offline: 由于被热插拔(HOTPLUGGED)或超过了内核配置的最大数量(kernel_max)而导致not online的CPU [~cpu_online_mask + cpus >= NR_CPUS]
- online: 在线且能够被调度的cpu [cpu_online_mask]
- possible: CPUs that have been allocated resources and can be brought online if they are present. [cpu_possible_mask]
- present: CPUs that have been identified as being present in the system. [cpu_present_mask]
上述内容的输出格式适用于cpulist_parse()函数(定义在头文件 linux/cpumask.h中)。 下面是相关的几个例子:
在第一个例子中,系统硬件可以支持64 CPUs,但是32-63号的cpu超过了内核配置的最大值32(0 … 31)。 2号及4-31号cpu是非在线的,但是但同时满足present和possible时这些可以变成online状态。
kernel_max: 31 offline: 2,4-31,32-63 online: 0-1,3 present: 0-31第二个例子中,NR_CPUS配置项为128,但是内核配置的possible_cpus=144。 系统中有4个cpus,同时2号cpu被认为设置为offline状态(这个是唯一可以变为online的cpu)
kernel_max: 127 offline: 2,4-127,128-143 online: 0-1,3 present: 0-3可以通过 cpu-hotplug.txt文件查看 possible_cpus=NUM 相关及更多其他内容。
CPU热拔插
在现代的体系架构中处理器引进了高级的错误上报和修正机制。 CPU架构允许对CPU进行分区,这使得单个CPU资源也可以提供一个可用的虚拟环境。 有很多支持NUMA的硬件都支持热拔插功能。 CPU的这种高级功能也需要内核的支持CPU的热拔插。
一个更具新意的CPU热插拔的应用是对SMP系统的挂起/恢复的支持。多核或HT技术使得在一台笔记本上也能运行SMP内核,但是目前的支持挂起/恢复的SMP技术还在研发中。
CPU热拔插相关的命令行开关:
-
maxcpus=n 限制启动时的cpu数为n。 如果系统中有4个cpu,同时使用了maxcpus=2的配置,那么启动时也只能启用2个cpu。可以在系统启动后再将其他cpu热插入。
-
additional_cpus=n 使用该选型限制可以热拔插的cpu数量。 通过该选项可以计算出系统能够支持的最大CPU个数: cpu_possible_mask = cpu_present_mask + additional_cpus 该选项只是用于ia64体系结构的cpu。
-
cede_offline={“off”, “on”} 使用该选项来 禁用/启动 offline 的处理器进入一种扩展状态: H_CEDE。 如果没有特殊说明, cede_offline 被设置为”on”。
-
possible_cpus=n x86_64体系架构使用该选项配置可拔插的cpu。 该选项的值会用于设置cpu_possible_mask。
CPU位图相关信息:
-
cpu_possible_mask: 系统中所有可用的可能的cpu位图。 在系统引导时,使用该项为per_cpu类型的变量申请内存, per_cpu 变量所占的内存在CPU热拔插时不会进行相应的扩展和释放。 一旦在启动是的探测阶段完成了对给位图的设置,它在整个系统运行过程中就是静态的, 也就是说在任何时候都无需设置或清除其中的任何一位。
-
cpu_online_mask: 当前系统中所有处于online的cpu的位图。 这个位图信息是在 __cpu_up()函数中设置的(当cpu能够执行内核调度和接受设备中断时), 当使用__cpu_disable()函数禁用某个CPU时,在所有的系统服务(包括中断在内)都被迁移到其它的CPU之前,需要清除此位图中相应的位。
-
cpu_present_mask: 当前系统中所有在位的cpu的位图。 并不是所有在位的cpu都是online状态的。 当物理的热插拔操作被相关的子系统(如,ACPI)处理之后,需要根据热插拔的情况对改位图进行相应的修改。目前还没有加锁规则。该位图典型的应用是在启动时初始化拓扑结构,而此时热插拔是禁用的。
在大部分情况下cpu位图都是只读的,你无需去修改它。在设置每一个per_cpu类型的变量是,总是使用 cpu_possible_mask/for_each_possible_cpu() 来进行循环处理。
不要使用除了cpumask_t以外的方式来描述一个CPU位图
#include <linux/cpumask.h> for_each_possible_cpu - Iterate over cpu_possible_mask for_each_online_cpu - Iterate over cpu_online_mask for_each_present_cpu - Iterate over cpu_present_mask for_each_cpu(x,mask) - Iterate over some random collection of cpu mask.下面的两个函数用于约束[inhibit]CPU的热插拔操作。这两个函数实际上是在操作cpu_hotplug.refcount。当cpu_hotplug.refcount非0时,不能改变cpu_online_mask的值。如果仅仅需要避免CPU被禁用,也可以在临界区前后使用preempt_disable()/preempt_enable()。但是需要注意的是,临界区中不能调用任何能够引起睡眠或将此进程调度走的函数。只要用来关闭处理器的函数stop_machine_run()被调用,preempt_disable()就会执行。
#include <linux/cpu.h> get_online_cpus() and put_online_cpus():CPU热拔插的FAQ:
Q: 如何配置内核是能CPU热拔插功能? A: 在对内核进行编译选项配置时,配置内核支持CPU热拔插功能:
"Processor type and Features" -> Support for Hotpluggable CPUs配置该选项是要确保 CONFIG_SMP 选项也是打开的。 如果需要支持SMP 的挂起/恢复功能,还要打开 CONFIG_HOTPLUG_CPU 编译选项。
Q: 支持CPU热拔插的架构有哪些? A: 在2.6.14及以后的内核中, 下面的体系结构都支持CPU热拔插功能。 i386 (Intel), ppc, ppc64, parisc, s390, ia64 and x86_64
Q: 如何测试新编译的一个内核是否支持热拔插功能? A: 可以观察sysfs文件系统中的一些文件来确认。 首先确认 sysfs 文件系统是否已经挂载。 执行 “mount” 命令。 注意命令的输出中是否有意下面的信息
... none on /sys type sysfs (rw) ...如果有上面的信息,就表示sysfs未挂载,执行下面的步骤
mkdir /sysfs mount -t sysfs sys /sys现在可以查看所有在位CPU的信息了。 下面的例子中展示的是一个有8个处理器的系统。
#pwd #/sys/devices/system/cpu #ls -l total 0 drwxr-xr-x 10 root root 0 Sep 19 07:44 . drwxr-xr-x 13 root root 0 Sep 19 07:45 .. drwxr-xr-x 3 root root 0 Sep 19 07:44 cpu0 drwxr-xr-x 3 root root 0 Sep 19 07:44 cpu1 drwxr-xr-x 3 root root 0 Sep 19 07:44 cpu2 drwxr-xr-x 3 root root 0 Sep 19 07:44 cpu3 drwxr-xr-x 3 root root 0 Sep 19 07:44 cpu4 drwxr-xr-x 3 root root 0 Sep 19 07:44 cpu5 drwxr-xr-x 3 root root 0 Sep 19 07:44 cpu6 drwxr-xr-x 3 root root 0 Sep 19 07:48 cpu7在每一个目录下,都包含一个 online 的文件,该文件可用于设置对应的处理器逻辑上的 online/offline的状态。
Q: 热拔插操作是否对应CPU物理上的增加和移除? A: 热拔插的使用与其字面上的意义并不完全一致。 配置了CONFIG_HOTPLUG_CPU选项后内核就支持CPU逻辑上的使能/禁止操作。 如果想要支持物理上的添加/删除,需要BIOS的回调以及平台上具有类似PCI设备热拔插的按钮。 配置了CONFIG_ACPI_HOTPLUG_CPU选项后就使得ACPI能够支持CPU在物理上的添加/删除操作。
Q: 怎么设置CPU逻辑上的禁用? A: 执行下面操作即可
echo 0 > /sys/devices/system/cpu/cpuX/online如果逻辑上禁用成功,可以通过检查 /proc/interrupts 文件来确认。 在该文件中,看不到禁用CPU的相关信息。 通过查看 /sys/devices/system/cpu/cpuX/online 文件确认对应cpu的当前状态,0表示offline,1表示online。
Q: 某些系统中,为什么不能移除CPU0? A: 一些体系架构中对于某些CPU会有特殊的依赖关系。 比如,在IA64中,我们可以发送平台中断给操作系统,也就是可修正的平台错误中断(CPEI)。 如果ACPI不支持这中断重定向到其他CPU功能(即中断只能发给特定的CPU),那么该CPU是不能被移除的。 在这种情况下,sysfs文件系统中对应的cpu0目录下就没有online文件。
Q: X86中的CPU0是否是可移除的? A: 是的。如果内核配置了编译选项 CONFIG_BOOTPARAM_HOTPLUG_CPU0=y,那么CPU0就是可以移除的。 另外还可以通过内核选项cpu0_hotplug来配置CPU0可移除。 但是某些特性需要依赖CPU0,如下:
- Resume from hibernate/suspend depends on CPU0. Hibernate/suspend will fail if CPU0 is offline and you need to online CPU0 before hibernate/suspend can continue.
- PIC interrupts also depend on CPU0. CPU0 can’t be removed if a PIC interrupt is detected. It’s said poweroff/reboot may depend on CPU0 on some machines although I haven’t seen any poweroff/reboot failure so far after CPU0 is offline on a few tested machines.
Q: 怎样确认某个CPU是不可移除的? A: 这个依赖于具体的实现, 某些架构对于这种CPU可能不存在online文件。 这种情况适用于能够提前判断该CPU不能移除的情况。 另外,还可以通过运行时检查实现,如当尝试移除最后一个CPU时,可以通过echo信息提示操作失败。
Q: 但对一个CPU进行逻辑上的移除时,具体会做哪些操作? A: 会发生下面的事情,排列是无序的。
- 内核模块会接收到 CPU_DOWN_PREPARE或 CPU_DOWN_PREPARE_FROZEN事件。 具体是哪个事件依赖于CPU被移除时,是否存在处于frozen的任务。
- 该CPU上的所有处理都被迁移到其他CPU上,具体迁移到哪个CPU是由每个任务当前的cpusset决定的, 它可能是所有处于online状态的CPU的子集。
- 所有需要上报到该CPU的中断都被迁移到其他CPU
- 定时器/中断下半部/tasklets也都会被迁移到其他CPU
- 一旦所有的服务都被迁移,内核就会调用一个体系相关的例程(__cpu_disable())来完成清理动作
- 当清理完成后,会上报事件 CPU_DEAD / CPU_DEAD_FROZEN
当CPU_DOWN_PREPARE事件处理函数被调用后,所有的服务都要被清理。 当CPU_DEAD处理函数调用时,不应该有任何东西还运行在该CPU。
Q: 怎么做才能使内核代码需要感知到CPU的接入和移除? A: 下面的代码表示接受到相应的通知时的处理。
#include <linux/cpu.h> static int foobar_cpu_callback(struct notifier_block *nfb, unsigned long action, void* hcpu) { unsigned int cpu = (unsigned long)hcpu; switch(action) { case CPU_ONLINE: case CPU_ONLINE_FROZEN: foobar_online_action(cpu); break; case CPU_DEAD_FROZEN: foobar_dead_action(cpu); break; }; return NOTIFY_OK; } static struct notifier_block foobar_cpu_notifier = { .notifier_call = foobar_cpu_callback, }需要在初始化函数中调用 register_cpu_notifier() 。 该初始化函数应该属于下面类型中的一个:
- early init(只有当启动处理器时才会调用的init函数)
- late init(当所有的CPU都online后才会调用的init函数)
当采用第一种情况时,需要在init函数中添加下面的代码
register_cpu_notifier(&foobar_cpu_notifier);当采用第二种情况时,需要在init函数中添加下面的代码
register_hotcpu_notifier(&foobar_cpu_notifier);如果在准备资源的时候出现问题会导致注册notifier失败。 这是会终止活动,然后发送一个CANCELED事件。
CPU_DEAD不应该失败,它仅仅是在通知一个好消息。当接收到一个BAD通知时,则意味着可能会发生坏事情。
Q: action调用次数与所有已经运行的CPU的数量不一致。 A: 是的,CPU notifiers只有当此新的CPU被使能(on-lined)或禁用(offlined)时才会调用。 如果你需要对系统的每一个CPU都执行相应的action,参考下面的代码。
for_each_online_cpu(i) { foobar_cpu_callback(&foobar_cpu_notifier, CPU_UP_PREPARE, i); foobar_cpu_callback(&foobar_cpu_notifier, CPU_ONLINE, i); } 如果你需要注册一个hotplug的回调处理,期望对已经处于online的CPU执行一些初始化错误,可以参考下面的方式: Version 1: (Correct) cpu_notifier_register_begin(); for_each_online_cpu(i) { foobar_cpu_callback(&foobar_cpu_notifier, CPU_UP_PREPARE, i); foobar_cpu_callback(&foobar_cpu_notifier, CPU_ONLINE, i); } /* Note the use of the double underscored version of the API */ __register_cpu_notifier(&foobar_cpu_notifier); cpu_notifier_register_done(); 注意下面的版本是不正确的方式,因为它有可能导致cpu_add_remove_lock 和 cpu_hotplug.lock之间的ABBA死锁。 Version 2: (Wrong!!!) get_online_cpus(); for_each_online_cpu(i) { foobar_cpu_callback(&foobar_cpu_notifier, CPU_UP_PREPARE, i); foobar_cpu_callback(&foobar_cpu_notifier, CPU_ONLINE, i); } register_cpu_notifier(&foobar_cpu_notifier); put_online_cpus(); 如果希望为已经处于online的CPU注册回调函数进行初始化时,一定要选用上面的Version 1。Q: 如果想对一种新的体系结构开发CPU热拔插的支持,最少需要哪些工作? A: 想要CPU热拔插基础框架能够正常工作,需要以下步骤:
* 确保Kconfig中添加了 CONFIG_HOTPLUG_CPU 的使能功能。 * __cpu_up() 体系结构中使能cpu的接口 * __cpu_disable() 体系结构中关闭cpu的接口, 当该函数返回后,内核不会再处理中断。 局部APIC定时器也会被关闭。 * __cpu_die() 这个接口实际上用于确认CPU真的已经关闭。最好参考下其他已经实现CPU热拔插的体系结构的代码。 __cpu_die()通常会等待某些 per_cpu的状态被设置,以确保处理器的关闭处理被正确的调用。Q: 如何确保某个正在执行某些特殊任务的CPU不能被移除? A: 有两种方式。 如果你的代码可以运行在中断上下文,可以使用 smp_call_function_single() ,否则使用 work_on_cpu() 。 注意 work_on_cpu() 函数执行很慢,有可能会导致out of memory。
int my_func_on_cpu(int cpu) { int err; get_online_cpus(); if (!cpu_online(cpu)) err = -EINVAL; else #if NEEDS_BLOCKING err = work_on_cpu(cpu, __my_func_on_cpu, NULL); #else smp_call_function_single(cpu, __my_func_on_cpu, &err, true); #endif put_online_cpus(); return err; }Q: 如何确定有多少个CPU可以热拔插? A: 到目前,ACPI都没有给出明确的信息。 Unisys的Natalie指出,ACPI的MADT(Multiple APIC Description Tables)可以将系统中可用的CPU标记为禁用状态。 Andi实现了一些简单的启发式方法,可以统计出MADT表中被禁用的CPU的个数,这些CPU就是可以用于热插拔的CPU。在没有被禁用的CPU的情况下,我们假设当前可用CPU的一半可以用于热插拔。
忠告:在ACPI2.0c以及以前的版本中, ACPI MADT仅能提供256个表项,因为MADT中的apicid字段仅有8位。 从ACPI3.0 开始,这个限制已经取消了, apicid字段已经扩展到了32bits。
用户空间的通知机制
在linux中,对设备的热拔插已经普遍支持了。 可以使用热拔插机制来自动配置网络,usb和pci设备。 一个热拔插事件可以唤醒一个代理脚本,用于执行某些配置任务。
在用户空间中可以添加 /etc/hotplug/cpu.agent 用于处理热拔插事件。
#!/bin/bash # $id: cpu.agent # Kernel hotplug params include: # ACTION=%s [online or offline] # DEVPATH=%s # cd /etc/hotplug ../hotplug.functions case $ACTION in online) echo `date` ":cpu.agent" add cpu >> /tmp/hotplug.txt ;; offline) echo `date` ":cpu.agent" remove cpu >> /tmp/hotplug.txt ;; *) debug_mesg CPU $ACTION event not supported exit 1 ;; esac
-
Linux X86引导协议
内容参考
- 内核文档:
简述
在x86的平台中,linux内核采用了一种相当复杂的引导方式。 在早期的时候内核是被设计为具有自我引导功能的,加上复杂的PC内存模型以及当时实模式Dos逐渐成为主流操作系统等原因,一步步演进导致了现在的这个结果。
目前,Linux/x86 包含以下几种版本的引导协议:
-
Old kernels: 仅仅支持zImage/Image。 有些早期的内核甚至可能都不支持命令行参数。
-
Protocol 2.00: (Kernel 1.3.73) 增加了对bzImage和initrd的支持, 使得boot loader和内核之间有了一种正式的通信方式。 setup.S被编译为可重定向的,但是仍然保留了传统setup区域的可写性。
-
Protocol 2.01: (Kernel 1.3.76) 增加了堆溢出的告警。
-
Protocol 2.02: (Kernel 2.4.0-test3-pre3) 提供了一个新的命令行(command line)协议。 降低了传统的内存上限。 该版本的协议没有覆盖传统的setup区域, 使得系统可以使用EBDA(Extended BIOS Data Area)从SMM或32-bit的BIOS入口更安全的进行引导启动。 此时zImage已经是不赞成使用,但是该版本仍然支持。
-
Protocol 2.03: (Kernel 2.4.18-pre1) 明确指定了bootloader可以使用initrd的高地址。
-
Protocol 2.04: (Kernel 2.6.14) 将syssize字段扩展为4字节。
-
Protocol 2.05: (Kernel 2.6.20) 提供了保护模式下内核的可重定位功能。 引入了relocatable_kernel 和 kernel_alignment字段。
-
Protocol 2.06: (Kernel 2.6.22) 增加一个字段用于保存引导的命令行的大小。
-
Protocol 2.07: (Kernel 2.6.24) 增加了半虚拟化引导协议。 引入了 hardware_subarch 和 hardware_subarch_data 字段,并在load_falgs中新增了KEEP_SEGMENTS标志。
-
Protocol 2.08: (Kernel 2.6.26) 增加了CRC32校验和ELF格式有效载荷功能。 引入payload_offset 和 payload_length 字段用于定位(locate)有效载荷(payload)。
-
Protocol 2.09: (Kernel 2.6.26) 增加了一个64-bit的指针字段, 指向setup_data结构体的单链表。
-
Protocol 2.10: (Kernel 2.6.31) Added a protocol for relaxed alignment beyongd the kernel_alignment added, new init_size and pref_address fields. Added extended boot loader IDS.
-
Protocol 2.11: (Kernel 3.6) 增加了一个字段handover_offset 用于保存EFI(Extensible Firmware Interface, 可扩展固件接口) handover协议入口地址的偏移量。
-
Protocol 2.12: (Kernel 3.8) 增加了一个xloadflags字段,扩展了struct boot_params结构体,使其能够在64bit系统中能够在4G以上的地址中加载bzImage和ramdisk。
内存布局
传统内存布局
早期的用于Image或zImage的内核加载器的内存布局如下图所示:
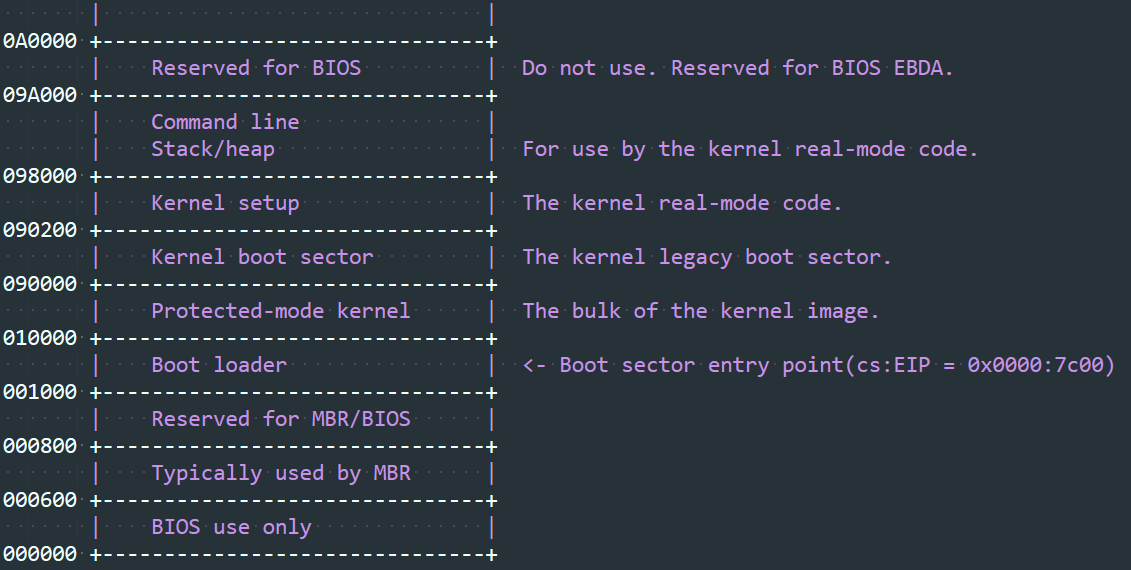
大于0x100000 的地址称为高内存(“high memory”)
0x1000 - 0x100000 之间的地址称为低内存(“low memory”)
当使用bzImage的时候,Protected-mode kernel会被重定位到0x100000(“high memory”),同时内核实模式块(kernel real-mode block),包括boot sector, setup, and stack/heap, 被设计为可重定位到 从 0x10000 到 0x100000 之间的任何位置。 不幸的是,在2.00和2.01版本中,0x90000+ 的内存区间仍然被内核用来存放实模式代码,2.02之后的版本解决了这个问题。
由于新的BIOS中包含了EBDA(Extended BIOS Data Area, 扩展BIOS数据域), 需要申请较多的内存,所以bootloader的内存上限(memory ceiling),即bootloader占用的低内存最高处的地址,越低越好。 bootloader通常应该使用”INT 12h”中的来检查低内存还有多少空间可以使用。
不幸的是,如果”INT 12h”上报没有足够的内存使用时,bootloader除了能报告一个错误为用户外,没有其他办法。 所以bootloader通常应该被设计为尽可能少的占用低内存空间。 对于zImage或者老的bzImage的内核(需要将数据写到0x90000段),bootloader应该要保证不会使用0x9A000+ 的地址空间,但是很多BIOS都会破坏这一点。
现代版本的内存布局
对于协议版本 >= 2.02 的使用bzImage的内核,内存布局如下图所示:
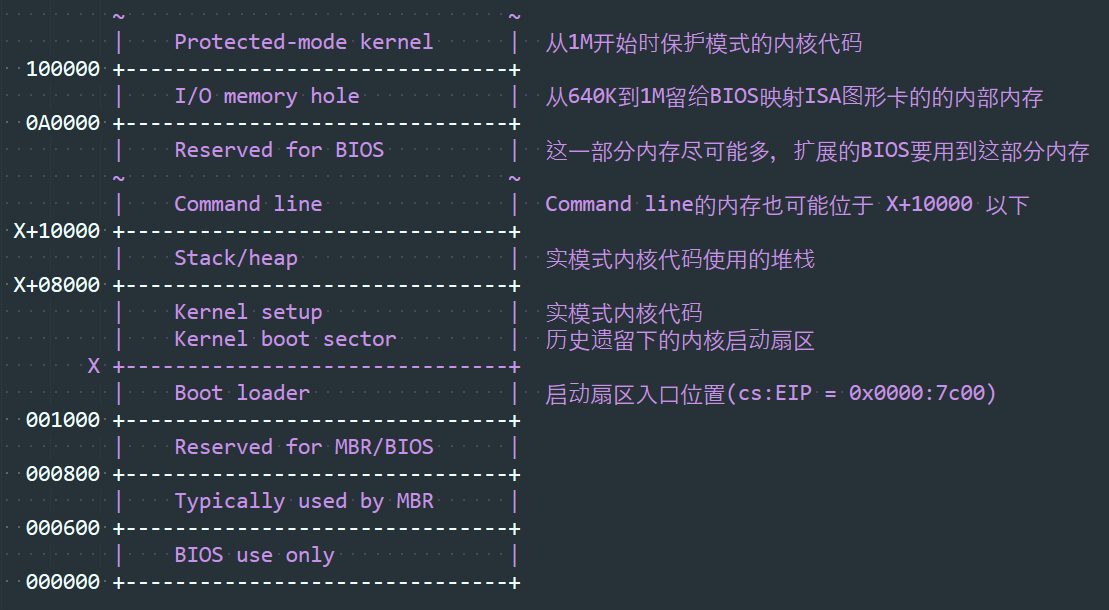
地址X应该在bootloader所允许的范围内尽可能的低。
实模式内核首部
在下文及内核引导序列(kernel boot sequence)中,一个扇区(sector)指的是512字节大小,与底层的介质真实的扇区大小是相互独立的。
内核加载的第一个步骤是加载实模式代码(boot sector 和 setup 代码),然后检查0x01f1偏移量处的首部信息。 实模式代码能达到32K,虽然bootloader有可能只加载前面的两个扇区(1K)就会去检查首部信息。
首部信息如下:
linux-4.4.23/arch/x86/include/uapi/asm/bootparam.h struct setup_header{ //setup 代码的大小,单位为512字节。 //如果该字段被设置为0, 那么会当作4来使用。 //在实模式下该代码包括boot sector(通常一个扇区大小) 加上 setup代码 __u8 setup_sects; //如果该字段不为0,表示root为readonly模式 //该字段已经不再推荐使用,通常采用命令行中的'ro'或'rw'代替 __u16 root_flags; //保护模式的代码大小,单位为16字节 //对于低于2.04版本的协议,该字段只有2个字节大小,所以对于设置了"LOAD_HIGH"标志的内核,大小是不可信的 __u32 syssize; //该字段已经废弃了 __u16 ram_size; //详情看见 SPECIAL COMMAND LINE OPTIONS __u16 vid_mode; //默认的根设备号,该字段已经不再推荐使用,通常采用命令行中的"root="来代替 __u16 root_dev; //值为0xAA55 __u16 boot_flag; //包含了x86的一个跳转指令,0xEB followed by a signed offset relative to byte 0x202 //该字段可以用来确定header的大小 __u16 jump; //Contains the magic number "HdrS" (0x53726448). __u32 header; //协议版本号,使用(major << 8) + minor格式,比如0x0204表示版本2.04,0x0a11表示不存在的版本10.17 __u16 version; //bootloader hook,详细参见 ADVANCED BOOT LOADER HOOKS __u32 realmode_swtch; //The load low segment (0x1000). 已废弃 __u16 start_sys; //如果该字段设置的是非零值,表示一个地址,在该地址加上0x200偏移量的地址指向一个人可以读懂的内核版本的字符串 //该字段的值应该小于 0x200*setup_sects //比如,如果字段的值为0x1c00,那么内核版本号的字符串保存在内核文件的0x1e00偏移处。 //如果该字段的值为0x1c00,那么它只有在setup_sects >= 15 的情况下才有效。 __u16 kernel_version; //如果bootloader被分配过ID,该字段里面填充的内容为0xTV, T表示bootloader的ID, V表示版本号 //如果没有被分配过ID,那么就填充0xFF //如果T的值大于0xD,那么需要向该字段的T位置写如0xE,然后将 T - 0x10的值填入 ext_loader_type字段。 //类似的,ext_loader_ver 字段用于扩展bootloader的版本 //例如, T=0x15, V=0x234,那么type_of_loader = 0xE4, ext_loader_type = 0x05 and ext_loader_ver = 0x23 //已经分配的bootloader的ID列表如下(十六进制): // 0 LILO (0x00 reserved for pre-2.00 bootloader) // 1 Loadlin // 2 bootsect-loader (0x20, all other values reserved) // 3 Syslinux // 4 Etherboot/gPXE/iPXE // 5 ELILO // 7 GRUB // 8 U-Boot // 9 Xen // A Gujin // B Qemu // C Arcturus Networks uCbootloader // D kexec-tools // E Extended (see ext_loader_type) // F Special (0xFF = undefined) // 10 Reserved // 11 Minimal Linux Bootloader <http://sebastian-plotz.blogspot.de> // 12 OVMF UEFI virtualization stack __u8 type_of_loader; //该字段表示一个位掩码 // Bit 0 (read): LOADED_HIGH // 0表示保护模式代码的加载位置为0x10000 (传统内存布局) // 1表示保护模式代码的加载位置为0x100000 (现代内存布局) // Bit 1 (kernel internal): KASLR_FLAG // 内核内部使用,表示KASLR的状态,1表示KASLR开启,0表示KASLR关闭。 // Bit 5 (write): QUIET_FLAG // 0表示打印早期信息,1表示不打印早期信息 // 该标志位要求内核不打印早期信息时,需要直接访问显示硬件设备。 // Bit 6 (write): KEEP_SEGMENTS // Protocol: 2.07+ // 0表示在进入保护模式时重新加载段寄存器 // 1表示不重新加载段寄存器 // Bit 7 (write): CAN_USE_HEAP // 1表示heap_and_ptr的值是有效的 // 0表示setup代码的功能将被禁止 __u8 loadflags; //使用2.00或2.01版本的协议时,如果实模式内核没有加载到0x90000时,在稍后的加载时会将代码移动到0x90000 //如果你想增加一些数据(如内核命令行),那么就填充该字段。 //The unit is bytes starting with the beginning of the boot sector //如果使用的是2.02及以上的协议或实模式的代码加载到了0x90000时,该字段可以被忽略 __u16 setup_move_size; //该字段表示在保护模式下的跳转地址。 该地址表示内核的加载地址,该地址可以被bootloader使用。 //该字段可能被修改的场景包括下面两个: // 1. 作为bootloader的hook(详情参见 ADWANCED BOOT LOADER HOOKS) // 2. 对于没有安装hook的bootloader需要在一个非标准地址加载一个可重定位的内核时,需要修改该字段的内容 __u32 code32_start; //initial ramdisk或ramfs的线性地址,如果没有initial ramdisk 或ramfs时,设置为0 __u32 ramdisk_image; //initial ramdisk或ramfs的大小,如果没有initial ramdisk或ramfs时,设置为0 __u32 ramdisk_size; //该字段被废弃 __u32 bootsect_kludge; //该字段表示setup stack/heap结尾地址相对于实模式代码其实地址的偏移,减去0x200 __u16 heap_end_ptr; //该字段用于type_of_loader中version的扩展。 最终的版本号为(type_of_loader & 0x0f) + (ext_loader_ver << 4) //2.6.31之前的内核版本不能识别该字段,但是在2.02及以上的版本中对该字段的设置仍然是安全的。 __u8 ext_loader_ver; //该字段用于type_of_loader中type的扩展。 //如果type_of_loader中的type为0xE,那么真实的类型应该是(ext_loader_type + 0x10) //如果type_of_loader中的type不为0xE,那么可以忽略该字段 //2.6.31之前的内核版本不能识别该字段,但是在2.02及以上的版本中对该字段的设置仍然是安全的。 __u8 ext_loader_type; //该字段用于保存内核命令行的线性地址。 内核的命令行可以被置于setup heap的end 至 0xA0000之间的任何位置 //内核的命令行没有必要一定被置于与实模式代码相同的64K的段中 //即使你的bootloader不支持命令行,最好也填充给字符,可以填充为空串(更好的情况是填充"auto") //如果该字段被设置为0,那么内核会假定为bootloader不支持2.02+以上的协议 __u32 cmd_line_ptr; //initial ramdisk/ramfs可能用到的最大地址。 //对于2.02或更早的协议来说, 不存在该字段,最大地址为固定的0x37FFFFFF //如果你的ramdisk的大小为131072,且该字段的值为0x37FFFFFF,那么ramdisk的起始地址为0x37FE0000) __u32 initrd_addr_max; //该字段表示可重定位内核的对齐方式。 可重定位的内核在内核初始化的时候按照这种方式进行重新排列 //从2.10版本的协议开始,该字段映射了内核的性能优化后的首选对齐方式。 //bootloader可以修改该字段为更小的对齐方式。 可以参考下面的min_alignment和pref_address字段 __u32 kernel_alignment; //如果该字段不为0,那么保护模式的内核可以被加载到任何满足kernel_alignment对齐方式的地址中。 //加载完成后,bootloader必须设置code_32_start字段为加载的代码的指针或boot的hook __u8 relocatable_kernel; //如果该字段的值不为0,2的该字段的幂次方表示内核引导的最小的对齐方式。 //如果bootloader确认使用该字段,那么需要更新kernel_alignment字段为希望的值 //通常情况下 kernel_alignment = 1 << min_alignment //出于采用未对齐的方式时可能会导致性能的降低,所以bootloader应该尽可能的采用 //从kernel_alignment到该字段之间的 power-of-two 的值的对齐方式。 __u8 min_alignment; // 该字段表示位掩码 // Bit0(read): XLF_KERNEL_64 // 1表示内核在0x200地址处有一个64-bit的入口地址 // Bit1(read): XLF_CAN_BE_LOADED_ABOVE_4G // 1表示kernel/boot_params/cmdline/ramdisk可以使用4G以上地址 // Bit2(read): XLF_EFI_HANDOVER_32 // 1表示内核支持32bit EFI handoff入口地址(handover_offset) // Bit3(read): XLF_EFI_HANDOVER_64 // 1表示内核支持64bit EFI handoff入口地址(handover_offset + 0x200) // Bit4(read): XLF_EFI_KEXEC // 1表示内核支持kexec EFI boot with EFI runtime support __u16 xloadflags; //命令行的大小的最大值(不包含结束符)。 这表示命令行可以包含最多cmdline_size个字符 //2.05及之前的版本,最大值为255 __u32 cmdline_size; //在半虚拟化的环境中,硬件底层的机制如中断处理,页表处理以及访问处理控制寄存器等需要不同的处理 //该字段允许bootloader通知内核当前的运行环境,具体为以下几种: // 0x00000000 The default x86/PC environment // 0x00000001 lguest // 0x00000002 Xen // 0x00000003 Moorestown MID // 0x00000004 CE4100 TV Platform __u32 hardware_subarch; //该字段目前在x86/pc下面没有使用,不要修改该字段 __u64 hardware_subarch_data; //如果该字段不为0,这表示payload相对保护模式代码起始地址的偏移量 //有效载荷有可能会被压缩。 不管是压缩还是未被压缩的数据都会采用相同的魔数 //当前支持的压缩方式有 gzip(magic: 1F8B or 1F9E), bzip2(magic: 425A) //LZMA(magic: 5D00), XZ(magic: FD37) 和 LZ4(magic: 0221) //未压缩的目前都是ELF格式(magic: 7F454C46) __u32 payload_offset; //The length of the payload __u32 payload_length; //该字段表示64-bit的物理地址,指向struct setup_data的单链表 //该单链表用来定义一个可扩展的启动参数传递机制,setup_data的结构体如下: // struct setup_data { // u64 next; //指向单链表的下一个节点 // u32 type; //used to identify the contents of data // u32 len; //data 的长度 // u8 data[0]; //保存实际的payload数据 // } //在启动过程中可能会修改该链表。 因此,当修改这个链表的时候,必须考虑到链表中存在节点的情况 __u64 setup_data; //该字段如果不为0表示内核的优先加载地址。 一个可重定向的bootloader应该能在该地址进行加载 //一个不可重定位的内核接受无条件的移动并能在该地址进行加载。 __u64 pref_address; //该字段表示大量的起始于内核运行时起始地址的连续的线性地址, //该起始地址是内核在其能检查自己的内存映射表之前所需的 //该字段不同于内核引导需要的总内存大小,而是被可重定位的bootloader用于帮助内核选择一个安全的加载地址。 //内核运行时起始地址的算法为: // if(relocatable_kernel) // runtime_start = align_up(load_address, kernel_alignment) // else // runtime_start = pref_address __u32 init_size; //该字段表示EFI handover协议入口地址相对内核映像起始地址的偏移量 //采用EFI handover协议来引导内核的bootloader会跳转到该偏移地址 //详细信息参考下面的 EFI HANDOVER PROTOCOL __u32 handover_offset; }Offset/Size ProtoVer Name Meaning Type 01F1/1 All1 setup_sects The size of the setup in sectors read 01F2/2 All root_flags If set, the root is mounted readonly modify(optional) 01F4/4 2.04+2 syssize The size of the 32-bit code in 16-bytes paras read 01F8/2 All ram_size DO NOT USE - for bootsect.S use only kernel internal 01FA/2 All vid_mode Video mode control modify(obligatory) 01FC/2 All root_dev Default root device number modify(optional) 01FE/2 All boot_flag 0xAA55 magic number read 0200/2 2.00+ jump Jump instruction read 0202/4 2.00+ header Magic signature “HdrS” read 0206/2 2.00+ version Boot protocol version supported read 0208/4 2.00+ realmode_swtch Boot loader hook (see below) modify(optional) 020C/2 2.00+ start_sys_seg The load-low segment(0x1000) (obsolete) read 020E/2 2.00+ kernel_version Pointer to kernel version string read 0210/1 2.00+ type_of_loader Boot loader identifier write(obligatory) 0211/1 2.00+ loadflags Boot protocol option flags modify(obligatory) 0212/2 2.00+ setup_mode_size Move to high memory size (used with hooks) modify(obligatory) 0214/4 2.00+ code32_start Boot loader hook (see below) modify(optional, reloc) 0218/4 2.00+ ramdisk_image initrd load address (set by bootloader) write(obligatory) 021C/4 2.00+ ramdisk_size initrd size (set by bootloader) write(obligatory) 0220/4 2.00+ bootsect_kludge DO NOT USE - for bootsect.S use only kernel internal 0224/2 2.01+ heap_end_str Free memory after setup end write(obligatory) 0226/1 2.02+3 ext_loader_ver Extended boot loader version write(optional) 0227/1 2.02+3 ext_loader_type Extended boot loader ID write(obligatory if(type_of_loader&0xf0) == 0xe0) 0228/4 2.02+ cmd_line_str 32-bit pointer to the kernel command line write(obligatory) 022C/4 2.03+ initrd_addr_max Highest legal initrd address read 0230/4 2.05+ kernel_alignment Physical addr alignment required for kernel read/modify(reloc) 0234/1 2.05+ relocatable_kernel Whether kernel is relocatable or not read(reloc) 0235/1 2.10+ min_alignment Minimum alignment, as a power of two read(reloc) 0236/2 2.12+ xloadflags Boot protocol option flags read 0238/4 2.06+ cmdline_size Maximum size of the kernel command line read 023C/4 2.07+ hardware_subarch Hardware subarchitecture write(optional, defaults to x86/PC) 0240/8 2.07+ hardware_subarch_data Subarchitecture-specific data write(subarch-dependent) 0248/4 2.08+ payload_offset Offset of kernel payload read 024C/4 2.08+ payload_length Length of Kernel payload read 0250/8 2.09+ setup_data 64-bit physical pointer to linked list or struct setup_data write(special) 0258/8 2.10+ pref_address Preferred loading address read(reloc) 0260/4 2.10+ init_size Linear memory required during initialization read 0264/4 2.11+ handover_offset Offset of handover entry point read 如果0x202偏移处(“header”字段)的magic不是”Hdrs”, 表示boot protocol的版本是老的。加载的是旧内核,会假设下面的参数被设置:
Image type = zImage initrd not supported Real-mode kernel must be located at 0x90000否则,”version”字段就包含了协议的版本。比如, 协议版本是 2.01 的话,version里面的值为 0x0201, 注意一定要确保填写的各个字段的值是当前这个protocol协议所支持的。
类型说明
read : 表示信息从kernel 到 bootloader write : 表示信息由bootloader填写 modify: 表示信息先从kernel 读到 bootloader,然后bootloader会做修改
所有普通意义上的bootloader都应该填写带有obligatory的字段。 对于需要采用非标准地址加载内核的bootloader需要填写带有reloc标志的字段, 其他的bootloader可以忽略带有该标志的字段。
所有字段的字节序为小端模式(x86)
映像校验和
从2.08版本的引导协议开始,对整个文件都会进行CRC-32进行校验,CRC-32校验算法采用典型的生成多项式0x4C11DB7和余数部分0xFFFFFFFF。 校验和被增加到文件后面,所以当对首部中的syssize大小的整个文件再次CRC校验时,结果应该总是为0。
内核命令行
内核命令行是bootloader与内核之间进行通信的一种重要方式。 有些内核命令行选项对bootloader也是有意义的。具体信息参见下面的 special command line options 部分。
内核命令行是一个包含结束符的字符串。 它的最大长度保存在cmdline_size字段中。 在2.06之前的协议中,最大长度为255个字符。 如果长度超过最大长度是,内核会自动截断。
在2.02及以后的协议版本中,内核命令行的地址被保存在首部的cmd_line_ptr字段中。 这个地址可以是setup head结尾到0xA0000之间的任何一个位置。
如果使用的2.02以前的协议,内核命令行的获取采用下面的方式:
At offset 0x0020 (word), "cmd_line_magic", enter the magic number 0xA33F. At offset 0x0022 (word), "cmd_line_offset", enter the offset of the kernel command line (relative to the start of the real-mode kernel). The kernel command line *must* be within the memory region covered by setup_move_size, so you may need to adjust this field.实模式下的内存布局
实模式代码启动时需要一个堆栈和一个用于存储内核命令行的内存空间。 这些内存需要在最低的1M空间内分配。
在现代机器中,通常都包含了EBDA区域,所以最好能尽可能少的使用最低的1M空间的内存。
在2.02以前的协议版本中,老的内核可能要求必须加载到0x90000的地址,此时要避免使用0x9a000以上的内存。
在2.02及以后的协议版本中,命令行没有必要一定与实模式启动代码在同一个64K数据段中。所以允许stack/heap使用64K的全部内存,然后在stack/heap上面再给命令行分配内存。
内核命令行不能保存在低于实模式代码的地址空间中,也不能保存到高内存地址中。
启动配置实例
作为一个简单的配置,假设实模式中段分配如下:
When loading below 0x90000, use the entire segment: 0x0000-0x7fff Real mode kernel 0x8000-0xdfff Stack and heap 0xe000-0xffff Kernel command line When loading at 0x90000 OR the protocol version is 2.01 or earlier: 0x0000-0x7fff Real mode kernel 0x8000-0x97ff Stack and heap 0x9800-0x9fff Kernel command lineSuch a boot loader should enter the following fields in the header:
unsigned long base_ptr; /* base address for real-mode segment */ if ( setup_sects == 0 ) { setup_sects = 4; } if ( protocol >= 0x0200 ) { type_of_loader = <type code>; if ( loading_initrd ) { ramdisk_image = <initrd_address>; ramdisk_size = <initrd_size>; } if ( protocol >= 0x0202 && loadflags & 0x01 ) heap_end = 0xe000; else heap_end = 0x9800; if ( protocol >= 0x0201 ) { heap_end_ptr = heap_end - 0x200; loadflags |= 0x80; /* CAN_USE_HEAP */ } if ( protocol >= 0x0202 ) { cmd_line_ptr = base_ptr + heap_end; strcpy(cmd_line_ptr, cmdline); } else { cmd_line_magic = 0xA33F; cmd_line_offset = heap_end; setup_move_size = heap_end + strlen(cmdline)+1; strcpy(base_ptr+cmd_line_offset, cmdline); } } else { /* Very old kernel */ heap_end = 0x9800; cmd_line_magic = 0xA33F; cmd_line_offset = heap_end; /* A very old kernel MUST have its real-mode code loaded at 0x90000 */ if ( base_ptr != 0x90000 ) { /* Copy the real-mode kernel */ memcpy(0x90000, base_ptr, (setup_sects+1)*512); base_ptr = 0x90000; /* Relocated */ } strcpy(0x90000+cmd_line_offset, cmdline); /* It is recommended to clear memory up to the 32K mark */ memset(0x90000 + (setup_sects+1)*512, 0, (64-(setup_sects+1))*512); }内核剩余部分加载
32-bit(非实模式)内核在起始于内核文件的(setup_sects+1)*512的偏移量处(如果setup_sects为0,强制修改为4)。 对于Image/zImage内核,需要加载在0x10000处,对于bzImage内核,需要加载0x100000处。
判断内核是否为bzImage的方式为protocol >= 2.00 且 loadflags = 0x01(LOAD_HIGH)
is_bzImage = (protocol >= 0x0200) && (loadflags & 0x01); load_address = is_bzImage ? 0x100000 : 0x10000;Image/zImage内核最大可以达到512K,所以使用的内存空间为0x10000 - 0x90000。 这就要求这种内核的实模式部分必须加载在0x90000处。 bzImage内核就有更多的灵活性。
SPECIAL COMMAND LINE OPTIONS
如果bootloader提供的命令行是用户输入的,那么用户可能期望使用下面的命令行选项。 即使这些参数对于内核来说没有什么意义,最好也不要删除这些参数。 bootloader的实现者需要增加新的命令行选项时,需要先将他们注册在 Documentation/kernel-parameters.txt ,确保没有与当前的内核选项有冲突。
vga=
可以是C语言中的integer类型(可以是十进制,八进制或十六进制数)也可以是字符串"normal"(表示0xFFFF),"ext"(表示0xFFFE),"ask"(表示0xFFFD)。 这个值会被保存在vid_mode字段中, 内核在解析命令行之前会使用这个字段。 mem=
是一个C语言的integer,后面可以跟着K,M,G,T,P或者E(忽略大小写),这些字符表示 <<10, <<20, <<30, <<40, <<50和<<60。 该参数选项表示内核在内存中的末尾。 它会影响到initrd存放的位置,因为initrd会存放在内存的末尾附近。 注意这个参数选项对内核和bootloader都有意义。 initrd=
指定了需要加载的initrd。 该文件和bootloader是相互独立的,对于某些bootloader(如LILO)不需要这个参数。 另外,某些bootloader添加了下面参数选项用于用户指定的命令行。
BOOT_IMAGE=
表示需要加载的启动映像,同样的,这个文件和bootloader也是相互独立的。 auto 表示内核不需要用户的交互直接启动。
如果bootloader增加了这些参数选项,强烈建议这些参数放在用户指定或配置型指定之前。否则,”init=/bin/sh” auto 这样的配置会让人产生困惑。
运行内核
内核的入口地址位于实模式内核段偏移0x20处。 这意味着,如果你加载的实模式内核代码位置为0x90000,那么内核的入口地址为 9020:0000。
在入口处,ds=es=ss 这些都指向实模式内核代码的起始地址(如果起始地址为0x90000那么ds=0x9000),sp 通常指向heap的顶部,同时需要禁止中断。 此外,为了预防内核bug,建议bootloader设置fs = gs = ds = es = ss。
/* Note: in the case of the "old" kernel protocol, base_ptr must be == 0x90000 at this point; see the previous sample code */ seg = base_ptr >> 4; cli(); /* Enter with interrupts disabled! */ /* Set up the real-mode kernel stack */ _SS = seg; _SP = heap_end; _DS = _ES = _FS = _GS = seg; jmp_far(seg+0x20, 0); /* Run the kernel */ADVANCED BOOT LOADER HOOKS
如果bootloader运行在一个非正常环境时(如运行在DOS下的LOADLIN),有可能无法获取标准内存。 这种情况下,bootloader需要使用hook了,内核会在合适的时间会调用hook。 hook就是最后的手段了。
重要: 所有的hook在调用时,都需要保存%esp, %ebp, %esi和%edi。
realmode_swtch: 在进入保护模式之前需要进行16位实模式下远子程序调用。 默认程序会禁止NMI。
realmode_swtch: A 16-bit real mode far subroutine invoked immediately before entering protected mode. The default routine disables NMI, so your routine should probably do so, too.
code32_start: A 32-bit flat-mode routine jumped to immediately after the transition to protected mode, but before the kernel is uncompressed. No segments, except CS, are guaranteed to be set up (current kernels do, but older ones do not); you should set them up to BOOT_DS (0x18) yourself.
After completing your hook, you should jump to the address that was in this field before your boot loader overwrote it (relocated, if appropriate.)** 32-bit BOOT PROTOCOL
For machine with some new BIOS other than legacy BIOS, such as EFI, LinuxBIOS, etc, and kexec, the 16-bit real mode setup code in kernel based on legacy BIOS can not be used, so a 32-bit boot protocol needs to be defined.
In 32-bit boot protocol, the first step in loading a Linux kernel should be to setup the boot parameters (struct boot_params, traditionally known as “zero page”). The memory for struct boot_params should be allocated and initialized to all zero. Then the setup header from offset 0x01f1 of kernel image on should be loaded into struct boot_params and examined. The end of setup header can be calculated as follow:
0x0202 + byte value at offset 0x0201In addition to read/modify/write the setup header of the struct boot_params as that of 16-bit boot protocol, the boot loader should also fill the additional fields of the struct boot_params as that described in zero-page.txt.
After setting up the struct boot_params, the boot loader can load the 32/64-bit kernel in the same way as that of 16-bit boot protocol.
In 32-bit boot protocol, the kernel is started by jumping to the 32-bit kernel entry point, which is the start address of loaded 32/64-bit kernel.
At entry, the CPU must be in 32-bit protected mode with paging disabled; a GDT must be loaded with the descriptors for selectors __BOOT_CS(0x10) and __BOOT_DS(0x18); both descriptors must be 4G flat segment; __BOOT_CS must have execute/read permission, and __BOOT_DS must have read/write permission; CS must be __BOOT_CS and DS, ES, SS must be __BOOT_DS; interrupt must be disabled; %esi must hold the base address of the struct boot_params; %ebp, %edi and %ebx must be zero.
** 64-bit BOOT PROTOCOL
For machine with 64bit cpus and 64bit kernel, we could use 64bit bootloader and we need a 64-bit boot protocol.
In 64-bit boot protocol, the first step in loading a Linux kernel should be to setup the boot parameters (struct boot_params, traditionally known as “zero page”). The memory for struct boot_params could be allocated anywhere (even above 4G) and initialized to all zero. Then, the setup header at offset 0x01f1 of kernel image on should be loaded into struct boot_params and examined. The end of setup header can be calculated as follows:
0x0202 + byte value at offset 0x0201In addition to read/modify/write the setup header of the struct boot_params as that of 16-bit boot protocol, the boot loader should also fill the additional fields of the struct boot_params as described in zero-page.txt.
After setting up the struct boot_params, the boot loader can load 64-bit kernel in the same way as that of 16-bit boot protocol, but kernel could be loaded above 4G.
In 64-bit boot protocol, the kernel is started by jumping to the 64-bit kernel entry point, which is the start address of loaded 64-bit kernel plus 0x200.
At entry, the CPU must be in 64-bit mode with paging enabled. The range with setup_header.init_size from start address of loaded kernel and zero page and command line buffer get ident mapping; a GDT must be loaded with the descriptors for selectors __BOOT_CS(0x10) and __BOOT_DS(0x18); both descriptors must be 4G flat segment; __BOOT_CS must have execute/read permission, and __BOOT_DS must have read/write permission; CS must be __BOOT_CS and DS, ES, SS must be __BOOT_DS; interrupt must be disabled; %rsi must hold the base address of the struct boot_params.
** EFI HANDOVER PROTOCOL
This protocol allows boot loaders to defer initialisation to the EFI boot stub. The boot loader is required to load the kernel/initrd(s) from the boot media and jump to the EFI handover protocol entry point which is hdr->handover_offset bytes from the beginning of startup_{32,64}.
The function prototype for the handover entry point looks like this,
efi_main(void *handle, efi_system_table_t *table, struct boot_params *bp)‘handle’ is the EFI image handle passed to the boot loader by the EFI firmware, ‘table’ is the EFI system table - these are the first two arguments of the “handoff state” as described in section 2.3 of the UEFI specification. ‘bp’ is the boot loader-allocated boot params.
The boot loader must fill out the following fields in bp,
o hdr.code32_start o hdr.cmd_line_ptr o hdr.ramdisk_image (if applicable) o hdr.ramdisk_size (if applicable)All other fields should be zero.
- 内核文档:
-
VMware中Ubuntu16.04安装使用
软件安装
openssh服务
-
软件包安装
sudo apt-get install openssh-server -
查看openssh服务是否启动
ps -ef |grep ssh进程ssh-agent是客户端,sshd为服务端,如果上述命令结果中有sshd表示服务已经启动,如果没有则需要使用命令手动启动。
-
启动、停止和重启 openssh-server的命令如下:
/etc/init.d/ssh start/stop/restart -
配置openssh-server 配置文件为 /etc/ssh/sshd_config
-
ubuntu中设置openssh-server开机自启动 在/etc/rc.local文件中添加 /etc/init.d/ssh start 即可
ncurses安装
配置内核编译选项的时候,出现下面的错误

解决方法就是安装ncurses
sudo apt-get install libncurses5-dev libncursesw5-devlibssl-dev安装
编译内核时出现下面的错误

解决方法就是安装 libssl-dev
sudo apt-get install libssl-dev
-
-
Linux Readme
内容参考:
-
内核文档: linux-4.4.23/README 链接
Linux kernel release 4.x
这是Linux 4版本的发行注解,仔细阅读这些内容,通过这篇文章可以了解如何安装内核以及出现错误时如何处理。
What is Linux
Linux是操作系统Unix的一个克隆版本,它是由Linus Torvalds和网络上一个松散组合的黑客团队共同完成的。它的目标是更符合POSIX和Single Unix规范标准。
Linux包含了现代成熟的Unix操作系统中的所有特性,如:真正的多任务(multitasking),虚拟内存(virtual memory),共享库(shared libraries),按需加载(demand loading),执行程序的共享写时拷贝(shared copy-on-write executables),合适的内存管理(momery management)以及支持IPv4和IPv6的多网络协议栈(multistack networking)。
Linux的发布遵循GNU GPL(General Public License),详情参见COPYING文件。
Linux运行的硬件环境
虽然Linux最初是为32位的x86架构(386或更高)的机器开发的,但是到目前为止,Linux还支持下面的硬件架构: Compaq Alpha AXP, Sun SPARC and UltraSPARC, Motorola 68000, PowerPC, PowerPC64, ARM, Hitachi SuperH, Cell, IBM S/390, MIPS, HP PA-RISC, Intel IA-64, DEC VAX, AMD x86-64, AXIS CRIS, Xtensa, Tilera TILE, AVR32, ARC and Renesas M32R。
Linux很容易移植到支持分页内存管理单元(paged memory management unit, PMMU)机制和GUN C编译(gcc)接口的32位/64位的硬件架构体系中。 Linux也可以移植到不支持PMMU的体系架构中,但是功能上会有一些限制。 Linux还能移植到它自己身上。你可以像用户空间的应用程序一样运行内核–这叫“用户模式 Linux”(UserMode Linux,简称UML)。
文档
-
目前已经有大量的电子版或纸质的针对Linux或关于通用Unix问题的文档。建议仔细查看Linux中的Documentation子目录中的LDP(Linux Documentation Project)。本文档不是作为系统的文档而提供的,有很多更好的资源适合你去阅读。
-
在Documantation子目录下有很多的readme文件,这些文件包含了内核特有的安装说明等内容。 Documentation/00-INDEX文件中列出了所有这些readme的简介。 Change文件中包含了新版本合入的问题信息,这些可以帮助确认是否需要升级内核。
-
Documentation/DocBook 子目录中包含了一些内核开发和使用的指南。这些指南可以被转换为多种格式:PostScript (.ps), PDF, HTML, & man-pages等。内核安装完成后,可以使用”make psdocs”,”make pdfdocs”,”make htmldocs”或”make mandocs”命令生成对应格式的文档。
内核源码安装
-
如果需要安装全量代码,首先将内核的tar包放到一个你拥有操作权限的目录(如home目录),然后执行解压操作,解压时使用实际的版本号替换命令中的X。
xz -cd linux-4.X.tar.xz | tar xvf -不要使用/usr/src/linux目录,该目录下包含了(通常不完全的)库头文件(library header)文件需要的内核头文件的集合。他们必须与库匹配,不应该因为内核变动导致有他们的匹配有变化。
-
也可以使用补丁方式在4.x发行版本之间进行升级。 补丁包采用xz格式进行发布。采用这种方式进行安装时,需要获取所有新的补丁包,进入内核源码的顶层目录(linux-4.x),然后执行下面的命令,执行时根据实际情况替换命令中的x。
xz -cd ../patch-4.x.xz | patch -pl如果想要移除备份文件(xxx~ 或xxx.orig),确保没有打失败的补丁(xxx# 或xxx.rej)。如果有打失败的补丁,那么前面的某个环节一定出现过错误。
与4.x内核的补丁不同,4.x.y(稳定版)的内核的补丁并不是递增的,而是在4.x的基础上替换的。例如,如果你的基础内核版本是4.0,你希望使用4.0.3版本的补丁,那么就不能安装4.0.1和4.0.2的补丁。同样的,如果你当前正在运行4.0.2的版本,同时希望升级到4.0.3,必须首先回退4.0.2的补丁然后再安装4.0.3的补丁。 在Documentation/applying-patches.txt文件中可以获取等更多的补丁升级方面的信息。
另外也可以使用patch-kernel脚本自动完成补丁升级。这取决于当前内核版本以及提供的补丁。
linux/scripts/pathc-kernel linux上面命令中的第一个linux表示内核代码的路径,补丁文件要么放在该路径下,要么放在第二个linux指定的目录下。
-
为了保证当前没有过期的.o文件或依赖关系,可以执行下面的命令:
cd linux make mrproper到现在为止,已经完成了内核代码的安装。
软件依赖
编译和运行4.x版本的内核需要更新一些软件包。可以查阅 Documentation/Changes文件获取所需软件的最低版本号及升级方式。注意如果使用很旧的软件包版本,可能会导致间接的错误,这些错误通常都很难定位跟踪,所以不要有在构建操作中出现问题后再升级软件包的想法。
构建内核路径
编译内核的时候,所有的输出文件都默认都会保存在对应的内核源代码目录下。使用编译参数(make O=output/dir)可以指定输出文件到其他目录(包括.config)。
例如:
kernel source code: /usr/src/linux-4.x build directory: /home/name/build/kernel可以实现用下面的命令来配置和构建内核:
cd /usr/src/linux-4.x make O=/home/name/build/kernel menuconfig make O=/home/name/build/kernel sudo make O=/home/name/build/kernel modules_install install注意,一旦使用了‘O=output/dir’选项,那么多有的make命令都要使用它。
配置内核编译
即使是在升级一个次要的版本时,也不要跳过这个步骤。每一个发行版本都会增加新的配置选项。如果没有按照要求配置时,可能会导致很多诡异的问题。如果想要保持当前已经存在的配置选项,可以使用”make oldconfig”命令,这样的话只需要配置新增的选项即可。
-
配置的命令有以下几种:
- “make config”——————-简单的文字界面方式
- “make menuconfig”—————基于文字的图形化界面方式,包含菜单、对话框和radiolists,
- “make nconfig”——————Enhanced text based color menus.
- “make xconfig”——————基于Qt的配置工具
- “make gconfig”——————基于GTK+的配置工具
- “make oldconfig”—————-根据已存在的./.config文件进行默认配置,只对新增的配置选项进行选择配置
- “make silentoldconfig”———-与上一个类似,不过避免了已经回答了的问题在屏幕上的杂乱显示。增加了一些升级依赖。
- “make defconfig”—————-根据 arch/$ARCH/configs/${PLATFORM}_defconfig 或 arch/$ARCH/defconfig文件自动生成与架构相关的config文件。
- “make ${PLATFORM}_defconfig”—-根据 arch/$ARCH/configs/${PLATFORM}_defconfig自动生成config文件。可以使用”make help”获取所有支持的平台架构的列表。
- “make allyesconfig”————-尽可能多的通过设置y来生成config配置文件
- “make allmodconfig”————-尽可能多的通过设置m来生成config配置文件
- “make allnoconfig”————–尽可能多的通过设置n来生成config配置文件
- “make randconfig”—————通过对设置赋随机值来生成config配置文件
-
“make localmodconfig”———–根据当前的config和系统中已经加载的模块生成config配置文件。禁用当前系统中未加载的所有的模块选项。 可以通过将lsmod的信息存储到一个文件中,将其传给另外一台机器,在这台机器上创建localmodconfig时将其传递给LSMOD参数。
target$ lsmod > /tmp/mylsmod target$ scp /tmp/mylsmod host:/tmp host$ make LSMOD=/tmp/mylsmod localmodconfig上述方式也可用于交叉编译的场景。
- “make localyesconfig” 与localmodconfig类似,只不过会该种方式会将所有module的选项从m转换为y。
可以从Documentation/kbuild/kconfig.txt文件中找到更多的关于linux内核配置工具的信息。
-
make config注意事项
-
配置了不必要的驱动会增加内核的大小,在某些场景下也会导致一些问题,如探测一个不存在的控制卡可能会导致系统中其他控制卡功能混乱。
-
编译内核时,如果Processor type 指定为386以上类型时,会导致内核不能在386下运行。内核在引导时会检测到该问题,然后放弃引导。
-
如果系统中有协处理器且内核编译配置了数学仿真时,内核会将协处理器当作数据仿真器来使用。内核可能会变得大一些,但是可以在不同的机器上去运行,而不用去管它是否真的存在数学协处理器。
-
“kernel hacking”配置项通常会导致内核变大或运行变慢(或者两个都有),在配置了用于查找内核问题的主动的例测项目时,甚至可能会导致内核变得不稳定。所以,要根据实际情况判断是否需要将”development”, “experimental”或”debugging”特性配置设置为’n’。
-
内核编译
-
确保gcc的版本大于等于3.2,可以查看 Documentation/Changes 获取更多信息。 请注意当前版本的内核仍然可以运行a.out形式的用户程序。
-
执行make命令生成一个压缩的内核映像。 首先确认lilo是否已经安装,如果安装了lilo(linux loader),就可以执行make install命令。 真正的执行安装动作时,需要使用root权限,但是在编译时不需要root权限。
-
如果将内核的某个部分配置成了modules,还需要运行 make modules_install 命令。
-
内核编译/构建时的输出信息:
通常情况下,内核编译系统运行在安静模式。 然而,有时候还是需要内核开发者确认编译,谅解或其他命令是否正确的执行。此时,可以使用”verbose”构建模式,只需要在make命令后面加上 V=1 的选项即可。
make V=1 all如果需要知道重复编译某些目标文件的原因时,使用 V=2。 默认情况下, V=0。
-
保留一个备份的内核防止新内核安装过程中出现错误。特别是对于开发版本的内核,因为其中包含了未调试的新的代码。在执行make modules_install命令之前,确保保留一个与之前备份的内核相对应的各模块的备份。
另外,在编译之前,可以使用”LOCALVERSION”配置选项在内核的版本后面添加一个唯一的后缀。”LOCALVERSION”在”General Setup”菜单中设置。
-
为了能够引导新的内核,必须拷贝内核的映像文件(如,编译后生成的 ../linux/arch/i386/boot/bzImage)到可以成功引导内核地方。
-
不使用引导程序(bootloader, 如LILO)而直接使用软盘启动内核的方式,现在已经不再支持。
如果需要通过硬盘引导Linux,可以使用LILO,通过在文件/etc/lilo.conf 中指定内核映像来引导。内核的映像文件通常是 /vmlinuz, /boot/vmlinuz, /bzImage 或/boot/bzImage。 使用新的内核时,保留原来内核映像的拷贝,然后将新内核映像覆盖原来的内核映像。然后,必须重新运行LILO来重新加载映射。如果没有执行这个步骤,不能引导新的内核。
重新安装LILO只需要运行/sbin/lilo即可。 可以编辑 /etc/lilo.conf 文件为旧的内核映像(如,/vmlinux.old)指定一个入口,从而停止运行新内核,重新运行旧内核。更多信息参见LILO文档。
重新安装完LILO后,所有的工作就完成了。关闭系统,重启然后开启新的Linux内核。
如果需要修改内核映像中的默认根设备,视频模式,ramdisk大小等,可以通过 ‘rdev’程序(或LILO的引导选项)完成,而不用重新编译内核来改变这些参数。
-
重启系统,开始新的内核之旅吧。
遇到问题怎么办
-
如果遇到的问题看起来像是内核的bug,首先查看 MAINTAINERS 文件确认出错部分是否有人维护。 如果没有的话,发送邮件给torvalds@linux-foundation.org,或者有可能的话也可以发送给相关的内核邮件列表。
-
在所有的bug报告中,如果是新问题,请说清楚出现问题的是那个内核,如何复现问题以及你做了哪些配置。 如果是旧问题,说明是什么时候发现问题的。
-
如果问题出现后,在屏幕或系统日志中出现了下面的信息:
unable to handle kernel paging request at address C0000010 Oops: 0002 EIP: 0010:XXXXXXXX eax: xxxxxxxx ebx: xxxxxxxx ecx: xxxxxxxx edx: xxxxxxxx esi: xxxxxxxx edi: xxxxxxxx ebp: xxxxxxxx ds: xxxx es: xxxx fs: xxxx gs: xxxx Pid: xx, process nr: xx xx xx xx xx xx xx xx xx xx xx或者类似的内核调试信息,请将这些完整准确的复制下来。这些信息对使用者来说可能是无用且不能理解的,但是它对于问题确认很有帮助。 dump上面的信息也很有帮助:它记录了内核崩溃的原因(上面的例子中,原因是使用了错误的内核指针)。 如果想了解更多的内核dump的信息,可以阅读 Documentation/oops-tracing.txt。
-
如果在编译的时候使用了 ‘CONFIG_KALLSYMS’ 配置项,可以获取到前面的dump信息。 否则,必须使用 “ksymoops”程序来获取dump信息。 通常优先选择设置 ‘CONFIG_KALLSYMS’ 配置项。 ksymoops 程序可以从下面的地址中获取: ftp://ftp.
.kernel.org/pub/linux/utils/kernel/ksymoops/ . -
在上面的dump调试信息中,如果能看懂EIP的含义是很有用的。 这个十六进制数目前来看对我们的帮助不大,它的真实值依赖于具体的内核配置。 首先我们获取到这个十六进制数(不包括 0010),然后在内核的namelist中查找这个十六进制数的地址位于那个函数中。
为了找到对应的内核函数,需要从内核的二进制文件(linux/vmlinx)中提取信息。 执行下面的命令:
nm vmlinux | sort | less这个命令会给出一个从小到大排好序的内核地址列表,通过它可以很容易的找到对应的内核函数。 需要注意的是,内核调试信息中给出的地址并不一定能够准确的与函数地址匹配(事实上都不能准确的匹配上), 所以不能够通过grep的方式对列表进行过滤。 这个命令输出的列表能够给出每个内核函数的起始地址。 只要找到起始地址小于EIP对应的地址,且紧跟这的下一个函数的起始地址大于EIP对应的地址,那么就定位到了出现问题的函数。
事实上,在提交的bug报告中,包含一些上下文信息是一个不错的主意。
如果因为某些原因不能提供上述信息(如使用的是一个预编译好的内核映像或其他原因), 那么就尽可能多的提供你的配置信息。更多信息参见 REPORTING-BUGS文件。
-
可以在一个运行的内核中是用gdb工具(只能读取信息,不能修改变量的值或设置断点)。 如果要使用这种方式,编译内核时需要设置 -g 编译选项, 修改 arch/i383/Makefile 文件,然后执行 make clean命令。 同时,需要在make config中使能 “CONFIG_PROC_FS” 配置项。
重启新编译的内核后,执行gdb vmlinux /proc/kcore 命令后就可以使用通用的gdb命令了。查看系统崩溃的命令为 “l *0xXXXXXXXX”(将XXXXXXXX替换为EIP中的实际值)。
使用gdb调试一个没有运行的内核时会失败,因为gdb会忽略内核编译时指定的起始地址偏移。
-
-
Sublime Text 3 使用说明
快捷键
-
ctrl + ` : 打开/关闭控制台(console)
-
ctrl + shift + p : 打开/关闭命令面板(command palette)
package control安装
在console中输入以下代码
import urllib.request,os; pf = 'Package Control.sublime-package'; ipp = sublime.installed_packages_path(); urllib.request.install_opener( urllib.request.build_opener( urllib.request.ProxyHandler()) ); open(os.path.join(ipp, pf), 'wb').write(urllib.request.urlopen( 'http://sublime.wbond.net/' + pf.replace(' ','%20')).read())插件安装与卸载
-
下载插件安装包,直接解压到【菜单->Perferences->Browse Packages…】目录;卸载的话就直接在此目录下删掉对应的插件文件夹就可以了。
-
使用package control安装
- 打开command palette, 输入install/remove/upgrade package, 回车,然后再输入要安装的插件名即可。
常用插件
-
ConvertToUTF8 : 用于解决文件中的中文乱码
-
Material Theme
-
Markdown Preview
-
使用快捷键 alt + b 可以在markdown文件所在目录生成对应的html文件
-
在 【Preferences】 -> 【Key Bindings - User】 中添加以下代码后,可以使用 alt + m 快捷键直接用浏览器显示对应的html格式
{"keys":["alt+m"], "command":"markdown_preview", "args":{"target":"browser", "parser":"markdown"}},
-
常用配置
自定义配置在 【Preferences】 -> 【Settings - User】 中添加
-
设置tab的空格数 ”tab_size”: 4
-
用空格替换tab ”translate_tabs_to_spaces”: true
-
显示空白字符 “draw_white_space”: “all”
-
自动换行 “word_wrap”: true
-