泛型算法概述
-
标准库并未给每个容器添加大量功能,而是提供了一组算法,这些算法的大多数都独立于任何特定的容器。这些算法是通用的(generic,或称泛型的):它们可以用于不同类型的容器和不同类型的元素。
-
大多数算法都定义在头文件algorithm中。标准库还在头文件numberic中定义了一组数值泛型算法。
-
通常情况下,这些算法并不直接操作容器,而是遍历由两个迭代器指定的一个元素范围来进行操作。算法遍历范围,对其中的每个元素进行一些处理。
-
虽然迭代器的使用令算法并不依赖于容器类型,但是大多数算法都使用了一个(或多个)元素类型上的操作(如==、< 、> 等)。不过大多数算法提供了一种方法,允许我们使用自定义的操作来代替默认的运算符。
-
泛型算法本身不会执行容器的操作,它们只会运行于迭代器智商,执行迭代器的操作。这种特性带来一个必要的编程假设:算法永远不会改变底层容器的大小。 算法可能改变容器中保存的元素的值,也可能在容器中移动元素,但永远不会直接添加或删除元素。
再探迭代器
-
除了为每个容器定义的迭代器之外,标准库还在头文件iterator中定义了额外几种迭代器,包括:
-
插入迭代器(insert iterator): 这些迭代器被绑定到一个容器上,可以用来向容器插入元素。
-
流迭代器(stream iterator): 这些迭代器被绑定到一个输入/输出流上,可以用来遍历所关联的IO流。
-
反向迭代器(reverse iterator): 这些迭代器向后而不是向前移动。除了forward_list之外的标注库容器都右反向迭代器。
-
移动迭代器(move iterator): 这些专用的迭代器不是拷贝其中的元素,而是移动它们。
-
插入迭代器
-
插入迭代器种类
-
back_inserter: 创建一个使用push_back的迭代器,it = back_inserter(c); 只有在容器类型支持push_back操作的情况下才能使用
-
front_inserter: 创建一个使用push_front的迭代器,it = front_inserter(c); 只有在容器类型支持push_front操作的情况下才能使用。
-
inserter: 创建一个使用insert的迭代器, it = inserter(c, iter); 第二个参数必须是一个指向c的迭代器。元素将被插入到iter迭代器所表示的元素之前。
-
-
插入迭代器操作
iter = value; 在iter指定的位置插入值value。 *it, ++it, –it 这些操作虽然存在,但是不会对it做任何事情。每个操作都返回it
iostream迭代器
-
虽然iostream类型不是容器,但是标准库定义了可用于这些IO类型对象的迭代器。
-
istream_iterator: 读取输入流, istream_iterator
t_iter(is); -
ostream_iterator: 向一个输入流写数据, ostream_iterator
t_iter(os);
-
-
istream_iterator
istream_iterator操作
istream_iterator<T> in(is); in_iter 从输入流is中读取类型为T的值 istream_iterator<T> in_eof; 读取类型为T的尾后迭代器 in1 == in2 in1 和 in2必须读取相同类型。如果它们都是尾后迭代器,或绑定到相同的输入,则两者相等 in1 != in2 同上 *in 返回从流中读取的值 in->mem 与(*in).mem的含义相同 ++in, in++ 使用元素类型所定义的»运算符从输入流中读取下一值 一个istream_iterator使用 » 来读取流,所以istream_iterator要读取的类型必须定义了输入运算符。
对于一个绑定到流的迭代器,一旦其关联的流遇到文件结尾或IO错误,迭代器的值就与尾后迭代器相等。
istream_iterator<int> in(cin), eof; // 从cin读取int vector<int> vec(in, eof); // 从迭代器范围构造vec, 从cin中读取int被用来构造vec当我们将一个istream_iterator绑定到一个流时,标准库并不保证迭代器立即从流读取数据。具体实现可以推迟读取数据,直到我们使用迭代器时才真正读取。 标准库保证的是,在我们第一次解引用迭代器之前,从流中读取数据的操作已经完成。
-
ostream_iterator
ostream_iterator操作
ostream_iterator<T> out(os); out将类型为T的值写到输出流os中 ostream_iterator<T> out(os, d); 每个值后面都输出一个d。d指向一个空字符结尾的字符数组 out = val 用 « 运算符将val写入到out所绑定的输出流中。val的类型必须与out可写的类型兼容 *out,++out,out++ 这些运算符是存在的,但是不对out做任何错误。每个运算符都返回out 运算符*和++实际上对ostream_iterator对象不做任何事情,因此忽略它们对程序没有任何影响,但是仍然推荐下面的写法。 这种写法中,流迭代器的使用与其他迭代器的使用保持一致。如果想要将此循环改成其他迭代器类型,修改起来很容易,且此循环的行为读起来更加清晰。
ostream_iterator<int> out_iter(cout, " "); for(auto e : vec) *out++ = e; // 赋值语句实际上将元素写到cout cout << endl; // 可以使用copy函数打印vec中的元素,这比写for循环更简单 copy(vec.cbegin(), vec.cend(), out_iter); cout << endl;可以为任何定义了输出运算符(«)的类型创建ostream_iterator对象。
反向迭代器
-
反向迭代器就是在容器中从尾元素向首元素反向移动的迭代器。对于反向迭代器,递增以及递减操作的含义是颠倒的。递增一个反向迭代器会移动到前一个元素,递减一个反向迭代器会移动到后一个元素。
-
除了forward_list以外,其他容器都支持反向迭代器。
-
通过调用reverse_iterator的base成员函数,可以将反向迭代器转换为普通迭代器。
-
从技术上讲,普通迭代器与反向迭代器的关系反映了左闭合区间的特性。关键点在于[line.crbegin(), rcomma) 和 [rcomma.base(), line.cend())指向line中相同的元素范围。为了实现这一点,rcomma和rcomma.base()必须生成相邻位置而不是相同位置, crbegin()和cend()也是如此
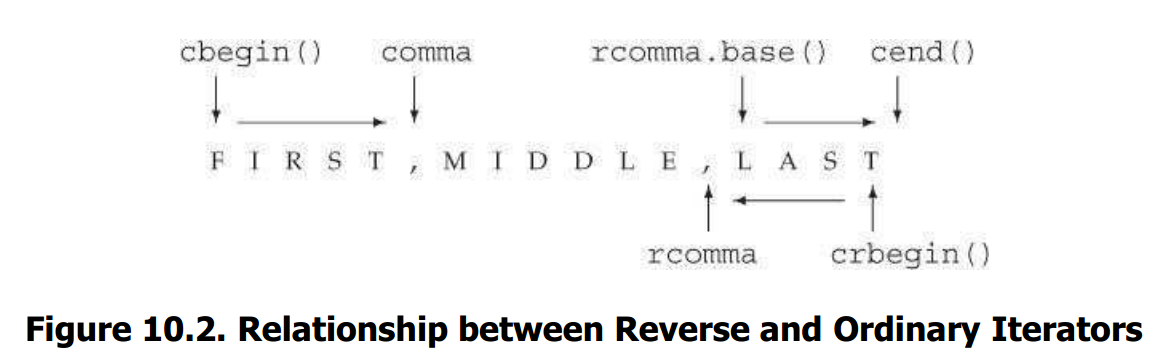
// 在一个逗号分割的列表中查找第一个元素 // line: FIRST,MIDDLE,LAST auto comma = find(line.cbegin(), line.cend(), ','); cout << string(line.cbegin(), comma) << endl; // 查找最后一个元素 auto rcomma = find(line.crbegin(), line.crend(), ','); // 逆序输出单词的字符 : TSAL cout << string(line.crbegin(), rcomma) << endl; // 正序输出单词的字符: LAST cout << string(rcomma.base(), line.cend()) << endl;
根据算法要求的迭代器操作进行的迭代器类别划分
-
任何算法的最基本的特征是它要求其迭代器提供哪些操作。算法所要求的迭代器操作可以分为5个迭代器类别(iterator category)。
输入迭代器 只读,不写;单边扫描,只能递增 输出迭代器 只写,不读;单遍扫描,只能递增 前向迭代器 可读写;多遍扫描,只能递增 双向迭代器 可读写;多遍扫描,可递增递减 随机访问迭代器 可读写,多遍扫描,支持全部迭代器器运算 除了输出迭代器之外,一个高层类别的迭代器支持底层类别迭代器的所有操作。
C++标准指明了泛型和数值算法的每个迭代器参数的最小类别。对每个迭代器参数来说,其能力必须与规定的最小类别至少相当。向算法传递一个能力更差的迭代器会产生错误。
-
输入迭代器
可以读取序列中的元素,一个输入迭代器必须支持
- 用于比较两个迭代器的相等和不相等运算符(== !=)
- 用于推进迭代器的前置和后置递增运算(++)
- 用于读取元素的解引用运算符(*);解引用只会出现再赋值运算符的右侧
- 箭头运算符(->),等价于(*it).member,即,解引用迭代器,并提取对象的成员
输入迭代器只用于顺序访问。只能用于单遍扫描算法。
算法find和accumulate要求输入迭代器;而istream_iterator是一种输入迭代器。
-
输出迭代器
可以看做输入迭代器功能上的补集 — 只写不读。输出迭代器必须支持
- 用于推进迭代器的前置和后置递增运算(++)
- 解引用运算符(*),只出现在赋值运算符的左侧
输出迭代器只能用于单遍扫描算法。用作目的位置的迭代器通常都是输出迭代器。例如,copy函数的第三个参数就是输出迭代器。
ostream_iterator是一种输出迭代器。
-
前向迭代器
- 支持输入和输出迭代器的所有操作,而且可以多次读写同一个元素。
- 只能在序列中沿一个方向移动。
算法replace要求前向迭代器。
forward_list容器上的迭代器是前向迭代器。
-
双向迭代器
- 可以正向/反向读写序列中的元素。
- 支持前向迭代器中所有操作。
- 还支持前置和后置的递减运算符(–).
算法reverse要求双向迭代器。
除了forward_list之外,其他标准库容器上的迭代器都是双向迭代器。
-
随机访问迭代器
- 提供在常量时间内访问序列中任意元素的能力。
- 支持双向迭代器的所有功能。
- 支持比较两个迭代器的关系运算符(< <= > >=)
- 迭代器和一个整数的加减运算(+ += - -=)
- 用于两个迭代器上的减法运算符(-),得到两个迭代器的距离
- 下标运算符(iter[n]),与*(iter[n])等价
算法sort要求随机访问迭代器。
array、deque、string和vector的迭代器都是随机访问迭代器,用于访问内置数组元素的指针也是。
谓词
-
谓词是一个可调用的表达式,其返回结果是一个能用作条件的值。标准库算法所使用的谓词分为两类:
- 一元谓词(unary predicate): 只接受单一参数
- 二元谓词(binary predicate): 接受两个参数
-
接受谓词参数的算法对输入序列中的元素调用谓词。因此,元素类型必须能转换为谓词的参数类型。
-
根据算法接受一元还是二元谓词,我们传递给算法的谓词必须严格接受一个或两个参数。但是,有时我们希望进行的操作需要更多的参数,超出了算法对谓词的限制。 为了解决此问题,需要使用另外一些语言特性,如lambda表达式和bind参数绑定。
lambda表达式
可调用对象
-
我们可以向一个算法传递任何类别的可调用对象(callable object)。
-
对于一个对象或一个表达式,如果可以对其使用调用运算符,则称它为可调用的。 即,如果e是一个可调用的表达式,则我们可以编写代码e(args),其中args是一个逗号分割的一个或多个参数的列表。
-
可调用对象的种类有:
- 函数
- 函数指针
- 重载了函数调用运算符的类
- lambda表达式
lambda简介
-
一个lambda表达式表示一个可调用的代码单元。可以将其理解为一个未命名的内联函数。与任何函数类似,一个lambda具有一个返回类型、一个参数列表和一个函数体。 与函数不同,lambda可能定义在函数内部。
-
lambda表达式的形式
[capture list] (parameter list) -> return type { function body }
capture list,捕获列表,是一个lambda所在函数中定义的局部变量的列表(通常为空) return type、parameter list 和 function body与任何普通函数一样,分别表示返回类型、参数列表和函数体。与普通函数不同的时,lambda必须使用尾置返回来指定返回类型。
参数列表和返回类型是可选的。捕获列表和函数体是必选的。 如果忽略返回类型,lambda根据函数体中的代码推断出返回类型。如果函数体只是一个return语句,则返回类型从返回的表达式的类型推断而来。否则,返回类型为void。
auto f = [] { return 32; }; cout << f() << endl; // 打印32 -
对于那种只在一两个地方使用的简单操作,lambda表达式是最有用的。 如果我们需要在很多地方使用相同的操作,通常应该定义一个函数,而不是多次编写相同的lambda表达式。 类似地,如果一个操作需要很多语句才能完成,通常使用函数更好。
如果lambda的捕获列表为空,通常可以用函数来替代它。但是,对于需要捕获局部变量的lambda,用函数来替代它就不是那么容易了。
向lambda传递参数
-
与普通参数不同的是,lambda不能有默认参数。因此,一个lambda调用实参数目永远与形参数目相等。
//按长度排序,长度相等的单词维持字典序 stable_sort(words.begin(), words.end(), [](const string &a, const string &b) { return a.size() < b.size(); } );当stable_sort需要比较两个元素时,它就会调用给定的lambda表达式。
lambda捕获列表
-
当定义一个lambda时,编译器生成一个与lambda对应的新的(未命名的)类类型。可以这样理解,当向一个函数传递一个lambda时,同时定义了一个新类型和该类型的对象:传递的参数就是此编译器生成的类类型的未命名对象。 类似的,当使用auto定义一个用lambda初始化的变量时,定义了一个从lambda生成的类型的对象。
默认情况下,从lambda生成的类包含一个对应该lambda所捕获的变量的数据成员。类似任何普通类的数据成员,lambda的数据成员也在lambda对象创建时被初始化。
-
值捕获
与传值参数类似,采用值捕获的前提是变量可以拷贝。与参数不同,被捕获的变量的值是在lambda创建是拷贝,而不是调用是拷贝。
void fcn1() { size_t v1 = 32; // 局部变量 // 将v1拷贝到名为f的可调用对象 auto f = [v1]{return v1;}; v1 = 0; auto j = f(); // j为32;f保存了我们创建它时v1的拷贝 auto f2 = [v1] () mutable { return ++v1; }; auto k = f2(); // k = 1 }默认情况下,对于一个值拷贝的捕获变量,lambda不会改变其值。如果我们希望改变它时,就必须在参数列表后面加关键字mutable。
-
引用捕获
一个以引用方式捕获的变量与其他任何类型的引用的行为类似。当我们在lambda函数体内使用此变量时,实际上使用的是引用所绑定的对象。
void fcn2() { size_t v1 = 32; auto f2 = [&v1] { return v1; }; auto f3 = [&v1] { return ++v1; }; v1 = 0; auto j = f2(); // j = 0, f2保存v1的引用而非拷贝 auto k = f3(); // j = 1, }当使用引用方式捕获一个变量时,必须保证在lambda执行时变量是存在的。
一个引用捕获的变量是否可以修改,依赖于此引用指向的是一个const类型还是一个非const类型。
一般情况下,应该尽量减少捕获的数据量,来避免潜在的捕获导致的问题。而且,如果可能的话,应该避免捕获指针或引用。
-
隐式捕获
可以让编译器根据lambda体中的代码来推断我们需要使用哪些变量。为了指示编译器推断捕获列表,应在捕获列表中写一个&或=。 & 告诉编译器采用引用捕获方式 = 告诉编译器采用值捕获方式
如果我们希望对一部分变量采用值捕获,对其他变量采用引用捕获,可以混合使用隐式捕获和显示捕获:
void biggies(vector<string> &words, vector<string>::size_type sz, ostream &os = cout, char c = ' ') { //os 隐式捕获,引用捕获方式;c显示捕获,值捕获方式 for_each(words.begin(), words.end(), [&, c](const string &s) { os << s << c; } ); //os 显示捕获,引用捕获方式;c隐式捕获,值捕获方式 for_each(words.begin(), words.end(), [=, &os](const string &s) { os << s << c; } ); }当混合使用隐式捕获和显示捕获时,捕获列表中的第一个元素必须是一个 & 或 =。此复合指定了默认捕获方式为引用或值。
当混合使用隐式捕获和显示捕获时,显示捕获的变量必须使用隐式捕获不同的方式。即,如果隐式捕获是引用方式,则显示捕获必须采用值方式。
lambda返回类型
默认情况下,如果一个lambda体包含return之外的任何语句,则编译器假定此lambda返回void。与其他返回void的函数类似,被推断返回void的lambda不能返回值。
// 正确
transform(vi.begin(), vi.end(), vi.begin(),
[] (int i) { return i < 0 ? -i : i; });
// 错误,不能推断lambda的返回类型
transform(vi.begin(), vi.end(), vi.begin(),
[] (int i) { if (i<0) return -i; else return i; });
// 正确
transform(vi.begin(), vi.end(), vi.begin(),
[] (int i) -> int
{ if(i<0) return -i; else return i; });
bind与参数绑定
-
很多地方都会使用,且需要捕获局部变量的lambda表达式。不能用普通的函数替代。此时可以使用bind标准库函数。它定义在#include
头文件中。 可以将bind函数看做一个通用的函数适配器,它接受一个可调用对象,生成一个新的可调用对象来“适应”原对象的参数列表。
调用bind的一般形式
-
一般形式为
auto newCallable = bind(callable, arg_list);newCallable 本身是一个可调用对象, arg_list 是一个逗号分割的参数列表,对应给定的callable参数。 即,当我们调用newCallable时,newCallable会调用callable,并传递给它arg_list中的参数。
arg_list中的参数可能包含形如_n的名字,其中n是一个整数。这些参数是“占位符”,表示newCallable的参数: _1 为newCallable的第一个参数,_2为newCallable的第二个参数,依次类推。 名字_n都定义在placeholders的命名空间中,而这个命名空间本身定义在std命名空间中。为了使用这些_1,_2的名字,需要声明
using namespace std::placeholders; bool check_size(const string &s, string::size_type sz); auto check6 = bind(check_size, _1, 6); // 使用lambda方式 auto wc = find_if(words.begin(), words.end(), [sz](const string &s) { return s.size() > sz;}); // 使用bind方式 auto wc = find_if(words.begin(), words.end(), bind(check_size, _1, sz));
使用bind重排参数顺序
-
可以使用bind绑定给定可调用对象中的参数或重新安排其顺序。例如,假定f是一个可调用对象,有5个参数
// g是一个有两个参数的可调用对象 auto g = bind(f, a, b, _2, c, _1); g(x, y); // 等价于f(a, b, y, c, x); -
绑定引用参数
默认情况下,bind的那些不是占位符的参数被拷贝到bind返回的可调用对象中。如果我们希望使用引用方式传递时,需要使用ref()或cref()。 ref 函数返回一个对象,包含给定的引用,此对象是可以拷贝的。 cref函数,生成一个保存const引用的类。 ref和cref也定义在头文件functional中。
ostream& print(ostrem& os, const string& s, char c) { return os << s << c; } // lambda 版本实现 for_each(words.begin(), words.end(), [&os, c](const string& s) { os << s << c; }); // 错误的bind版本,不能拷贝os for_each(words.begin(), words.end(), bind(print, os, _1, c)); // 正确的bind版本 for_each(words.beging(), words.end(), bind(print, ref(os), _1, c));